
Stathes P. Hadjiefthymiades, Drakoulis I. Martakos
Department of Informatics, University of Athens
TYPA Building, Panepistimioupolis
Ilisia, 15784 Athens, Greece
Tel: +031 7248154, Fax: +301 7219561
shadj@di.uoa.gr,
martakos@di.uoa.gr
The phenomenal growth that the World Wide Web (WWW) service currently experiences necessitates the adaptation of legacy information systems like RDBMSs or full-text search systems to HTTP servers. Existing standards for performing this adaptation (i.e. CGI), although well established, prove highly inefficient throughout periods of heavy load (multiple hits per unit time). In this paper, after reviewing all the relevant mechanisms, we propose a generic architecture which adheres to the existing standards and client/server model and alleviates the performance handicap of classical database gateways. The performance evaluation which was realised as part of this research effort revealed a noteworthy superiority of the proposed architecture with respect to monolithic (non-client/server) CGI based approaches.Keywords: WWW-to-DBMS links, CGI, RDBMS, Dynamic SQL, Inter-Process Communication
WWW servers carry specialised software, called HTTPd (HTTP demon), which receives and dispatches HTTP requests. The need to incorporate information sources other than static HTML files (e.g. databases) forced the standardisation of the communication between HTTPds and application programmes. Such standardisation efforts led to the specification of Common Gateway Interface (CGI) [3]. Throughout the evolution of WWW, key industrial players like Netscape and Microsoft introduced their own, proprietary mechanisms (e.g. NSAPI, ISAPI) as enhanced and elaborated alternatives for performing similar tasks (dynamic generation of pages, extension of basic server's functionality). However, there is an on-going discussion in the WWW community about those two schools of thought (CGI Vs proprietary, C callable APIs). Both alternatives are faced with scepticism due to their characteristics [4]. As shown below, the strengths of CGI are the weaknesses of proprietary APIs and vice versa.
CGI is the most widely deployed mechanism for integrating HTTP servers with other information systems. Its design does not scale to the performance requirements of contemporary applications. Moreover, CGI applications do not run in the HTTPd process. In addition to the performance cost, this means that CGI applications can't modify the behaviour of HTTPd's internal operations, such as logging and authorisation. Finally, CGI is viewed as a security issue by some server operators, due to its connection to a user-level shell. The APIs introduced by Netscape, Microsoft or other servers (e.g. Apache) can be considered an efficient alternative to CGI. This is mainly attributed to the fact that server APIs entail a considerable performance increase and load decrease as gateway programs run in or as part of the server processes (instead of starting a new process for each new request as CGI specifies). Furthermore, through the APIs, the operation of the server process can be customised to the individual needs of each site. The main disadvantages of the API solution include the limited portability of the gateway code which is attributed to the absence of standardisation (completely different syntaxes and command sets). The choice for the programming language in API configurations is rather restricted if compared to CGI (C Vs C, Perl, Tcl/Tk, Rexx, Python and a wide range of other languages). As API-based programmes are allowed to modify the basic functionality offered by the HTTP demon, there is always the concern of buggy code that may lead to core dumps or other similar problems.
One form of gateway programmes which has drawn the attention of the WWW community during the past years, concerns the connectivity to relational database systems (RDBMSs). Such connectivity has been a research issue for a prolonged period of time [5], [6], [7] while many relevant tools emerged in the software market [8], [9]. Issues-problems associated with the deployment of database gateways include: portability among systems, generality, compliance to standards, performance, stateful/stateless orientation. In [10] a framework for the deployment of databases on the WWW was proposed. The main advantages of this framework were generality and compliance to existing standards. In this paper the performance problem of database gateways is also addressed. Existing database gateways, due to their support for CGI or proprietary APIs, inherit their strengths and weaknesses (as they have been discussed in the previous paragraph). We pursue the design of architecture and the development of a software prototype in which performance improvement is achieved by adherence to the wide-spread & portable CGI and the generic database access mechanism proposed in [10].
This paper is structured as follows. Section II discusses the performance behaviour of classical database CGI gateways and identifies the need for their re-design. This need is attributed to the large number of CGI scripts which are independently spawned by the HTTPd during periods of heavy load. Each script reserves resources by establishing communication with the serving processes of the management system. This activity is extremely costly and thus, degrades the speed of database access. Sections III and IV present an innovative software architecture which reduces - eliminates the need for such a costly operation and thus, improves the associated performance. We propose a client/server configuration in which small, concise and portable clients, complying to the CGI standard, are spawned by the HTTP demon; their communication with the management system is possible only through a properly structured database agent (server) which, in turn, is both portable and generic. A protocol has been designed for this communication taking into account the individualities of both the relational system and the HTTP demon. In this paper, we focus on those gateways that simply, retrieve information (dispatch SQL SELECT statements). Technical issues, associated with the development of this client/server architecture, are discussed in detail, including optimisations (fragmentation of responses, etc.). In Section V we present the results of a series of tests realised for the performance evaluation of a prototype built using the proposed architecture. Monolithic versions of CGI scripts, which provided identical functionality, were also subjected to the same tests to help identify the qualitative benefits obtained by the discussed optimisation. Finally, Section VI points out areas of architecture-prototype improvement and further research.
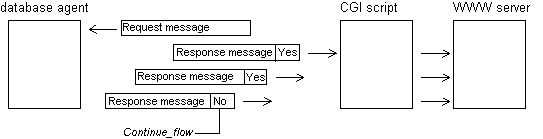
Env (environment) represents active WWW browsers (two in the scenario sketched in Fig.1). Requests are transmitted to the WWW server (HTTPd) using the HyperText Transfer Protocol in conjunction with the URL encoding scheme. The two requests shown pertain to the same script and not some static HTML page.
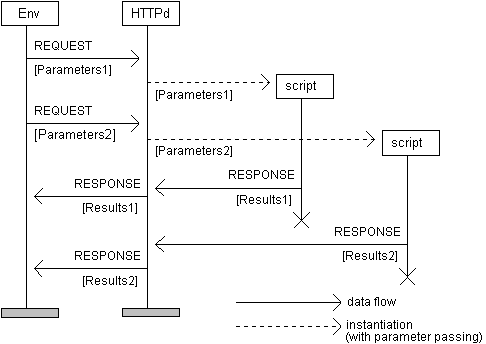
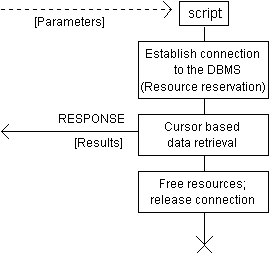
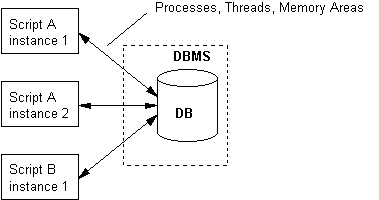
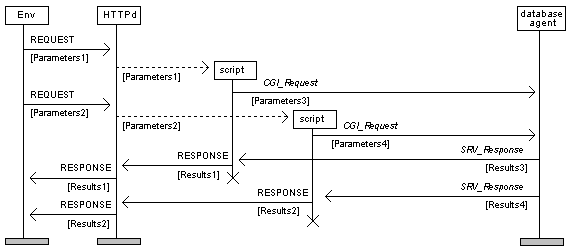
The agent receives SQL statements from the CGI scripts, executes them on the designated database (which has already been opened and activated) and returns the results to the originators of the respective requests. In this architecture, CGI processes do not interface directly to the DBMS. Their only engagement (prior to the database access) is the formulation of SQL statements on the basis of information (parameters) conveyed in the HTTP request. The flowcharts presenting the internal structure of both the client (script in Figure 4) and the server (database agent in Figure 4) processes are provided in Figures 5.a and 5.b respectively.
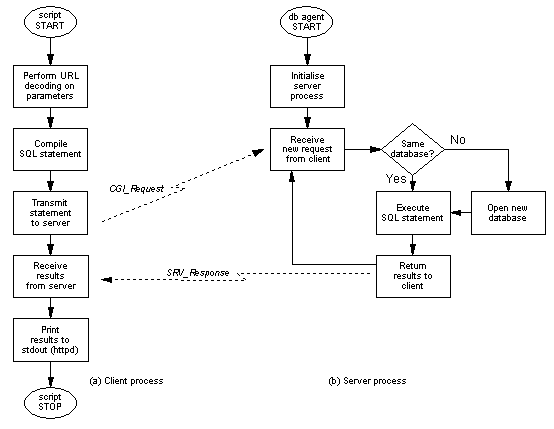
The protocol under discussion comprises only two message structures. The first refers to requests transmitted by CGI scripts-clients. As shown in Figure 5.a, CGI scripts are responsible for URL decoding the activation parameters (contents of QUERY_STRING or standard input, name-value pairs, etc.), compose a request (CGI_Request) intended for the server process and proceed with its transmission. Such message should indicate the database to be accessed, the SQL statement to be executed, an identifier of the transmitting entity as well as the layout of the anticipated results (with respect to the HyperText Markup Language; HTML). In Figure 6 we provide the Backus-Naur Form (augmented BNF [12]) of CGI_Request.
|
CGI_Request = database_name sql_statement [client_identifier] results_layout database_name = *OCTET sql_statement = *OCTET client_identifier = *DIGIT ; UNIX PID results_layout = "TABLE" | "PRE" | "OPTION" |
|
SRV_Response = response_from_db_server continue_flow response_from_db_server = *OCTET continue_flow = "YES" | "NO" |
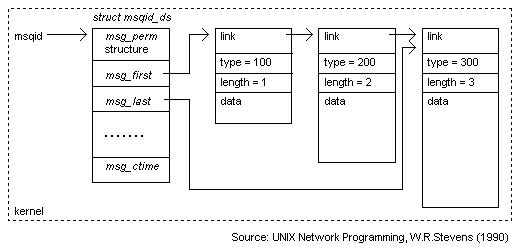
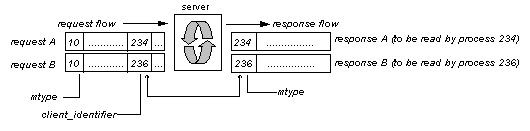
A variety of message structures can be stored in the same queue (as shown in Figure 8 where adjacent messages have different lengths). Furthermore, messages can be placed or retrieved from the structure by any active process of the system. This IPC mechanism is not limited to just two processes as other mechanisms like pipes and FIFOs. Message queues are not based on the stream model where the exchanged data aren't structured. As the prototype was programmed in C and Embedded SQL, it was possible to store whole struct instances to the queue supporting the architecture. No additional manipulation of messages was required in contrast to stream based IPC mechanisms that require communicating parties to a-priori agree on a certain protocol for the interpretation of the data stream. Berkeley Sockets can also accommodate the protocol described in Section III and are the choice when network communication is involved between scripts and the database agent (see Section VI).
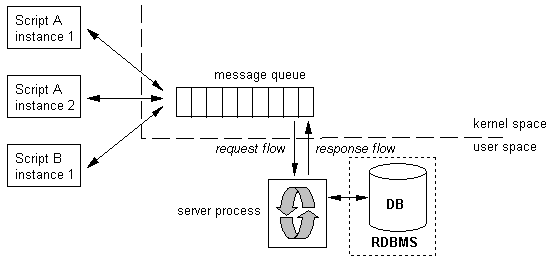
For the deployment of the architecture only one message queue was used leading to what is shown in Figure 9. This queue is the recipient of messages generated by the CGI scripts as well as the responses produced by the server process. The queue is created by the server process once, upon system's initialisation.
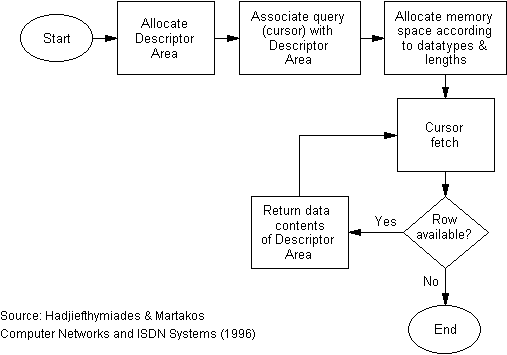
When executing a query in Dynamic SQL, space in memory is allocated ad hoc, according to the contents of the system Descriptor Area (DA). DA is a fully standardised (X/Open) memory structure (a perplexing combination of pointers and arrays) indicating the number of columns fetched as well as their particular characteristics (datatype, length, name, precision, scale, etc.). Furthermore, DA contains pointers to the actual data. As the database access through 3-GLs (i.e. C, COBOL) is cursor based, pointers to data are updated each time a new row is fetched by the system. In our case, the server process scans the whole Descriptor Area after each invocation of the cursor FETCH command and prints its contents according to the results_layout field of the CGI_Request. The dynamic mechanism for database access is presented in the flowchart of Figure 13.
Results are returned by the database agent in three different formats which are specified in the results_layout field of CGI_Request. HTML Tables ("TABLE") and preformatted text ("PRE") are mainly used for the tabular presentation of query results. The "OPTION" alternative is used for the population of combo boxes intended for Query By Example (QBE) forms [10]. QBE forms allow the complete specification of query criteria by the end-user.
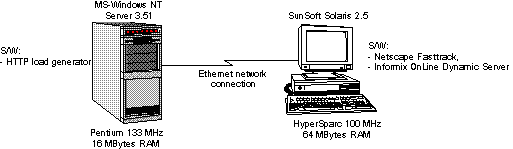
Figure 14. Hardware configuration for performance evaluation
The experiment consisted of a series of trials in which a pinger program directed a number of HTTP requests towards the server (load generator). The pinger program executed on a MS-Windows NT Server (ver. 3.51) hosted by a Pentium 133 MHz machine with 16 MB of RAM. Both machines were interconnected by a 10Mbps Ethernet LAN and were isolated by any other computer to avoid additional traffic which could endanger the reliability of the experiment. Moreover, both systems were running only those processes needed in support of the experiment.
The pinger program was configured to request data from a CGI script using the GET method. The experiment was repeated twice: once for a typical CGI script and once for the discussed prototype (answers from the database agent were fragmented to 512 bytes messages). In both cases, the designated database access involved the exhaustive read of a relational table (SELECT * ....). Furthermore, the number of tuples extracted from the database as well as the HTML page returned to the pinger were identical. The size of the HTML page produced was 2.212 KB. The tuples extracted by the database were embedded in an HTML table (results_layout="TABLE"). It should be noted that the pinger program doesn't perform caching in contrast to typical WWW browsers.
The monolithic, typical CGI script under evaluation was also programmed in C and Embedded SQL. For the deployment of the script we used common Embedded SQL commands in conjunction with hardcoded definitions; we did not use the dynamic access mechanism (DA) presented in Section IV and [10]. Script's internal structure, although of a static character, is the most popular among the developers of database gateways in WWW sites.
The Fasttrack server is capable of forking a set of slave processes upon its initialisation (a mechanism also known as "pool of processes"). The master process accepts the requests from clients and passes the file descriptor to one of the slaves. This architecture reduces (or eliminates) the need to fork a new process for each incoming request thus, reducing the response time experienced by clients. In the experiment documented herein, Fasttrack was configured to pre-fork 4 processes (with up to 32 threads each). Access control was disabled in the HTTP demon (requests were dispatched irrespective of the IP address of their originator).
The pinger program was configured to simulate the traffic caused by up to 18 HTTP clients (starting from 2). Each trial consisted of 100 repetitions of the same request, thus allowing the experiment to reach a steady state. Upon trial's completion the pinger program updates an activity log with the following information:
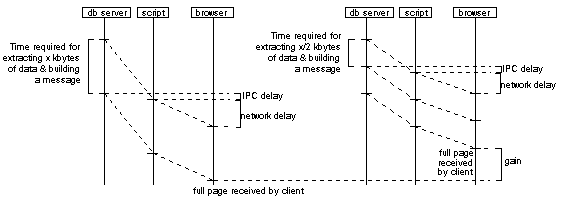
From the above metrics we considered the first three as the most important and worth mentioning. Bytes Send and Bytes Received were recorded and compared with the purpose of verifying that the total size (in bytes) of HTTP requests and responses were equal in both trials. The performance that both solutions (monolithic Vs client/server with responses fragmented to 512 bytes) demonstrated with respect to the considered metrics is illustrated in the following figures.
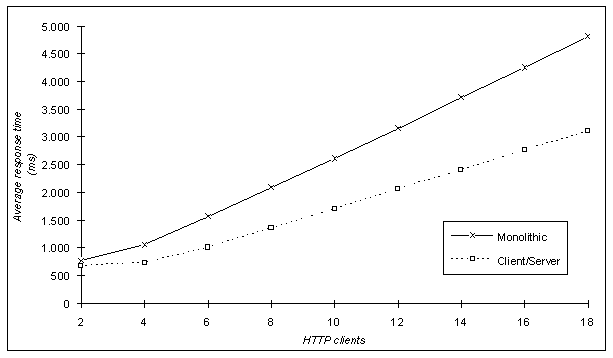
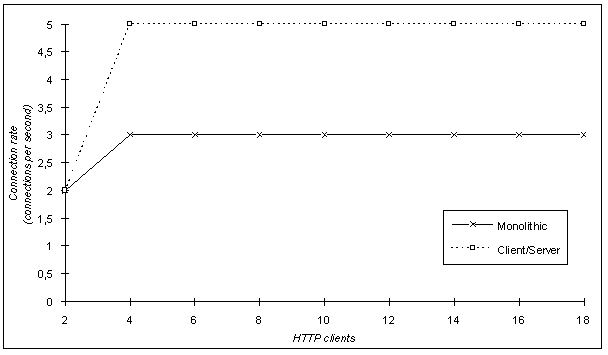
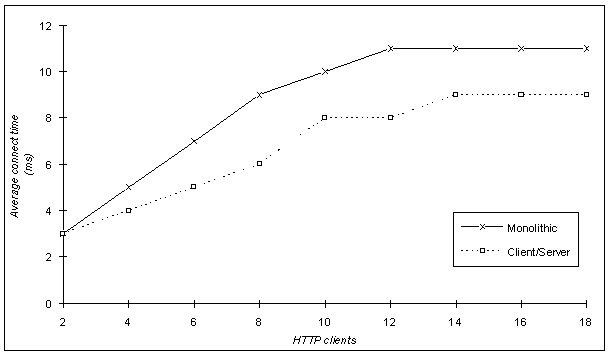
Apart from the comparative analysis of the two scenarios, we performed some individual measurements of the client/server solution with responses fragmented to 1024 bytes. Such measurements cover up to 10 simultaneous users (threads of the pinger utility) and were plotted in conjunction with the results of the 512 bytes scenario. We only present the Connect Time (Figure 18) and Response Time (Figure 19) as functions of the number of HTTP clients since the Connect Rate was equal to that recorded in the 512 bytes case.
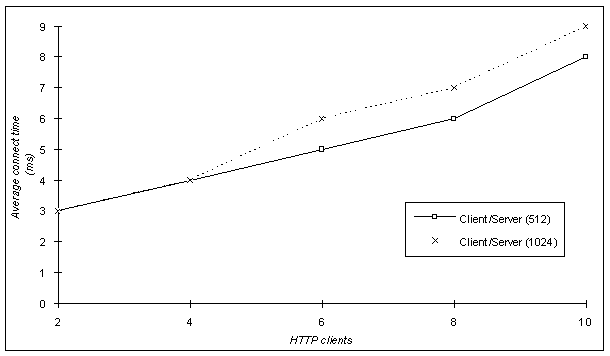
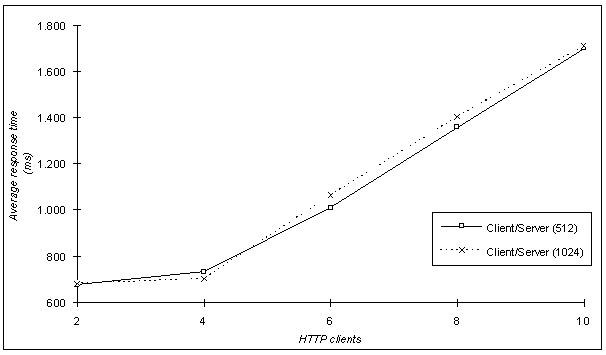
Figure 19. Response time Vs number of clients.
It was shown that the prototype adopting the proposed client/server architecture and related protocols performed significantly better than monolithic CGI scripts, developed using typical database APIs (Embedded SQL). Standardised mechanisms like Message Queues and Dynamic SQL were used to ensure the portability of the prototype to other UNIXes and relational management systems (X/Open compliant). Further provision was taken to optimise the operation of the client/server architecture using the fragmentation of responses produced by the database agent.
It was also demonstrated how two software components, the database agent that has an unlimited life-time (demon process) and the client processes (CGI scripts) whose execution is terminated as soon as results are passed to the server, can be combined to deliver WWW services at acceptable response times. The design of the database agent provides for the preservation of state information between consecutive accesses. In the prototype, the database agent simply remains attached to the database accessed by the most recently dispatched request. This basic architecture is currently expanded to deal with more complex situations and thus, resolve the stateful/stateless problem associated with the operation of the WWW [17]. CGI specifies a set of variables which could be used for the identification of individual sessions [3].
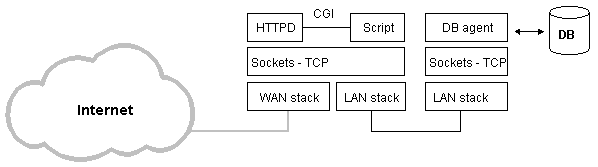
Message Queues, due to their kernel based operation, limit the communication between CGI processes and the database agent to a single computer which should host both the WWW server (HTTPd) and the database management system. Although this centralised configuration is encountered in most of the DB-powered WWW sites it should be considered as a special case of a distributed set-up where the database server operates on a different machine from that of the HTTP demon (Figure 20). In such case, the messages introduced in Section III should be exchanged over a network connection using a transport layer protocol like TCP. Berkeley Sockets [18] constitute an IPC mechanism which could be used efficiently in both the centralised and distributed configurations and thus, satisfy the posed requirement for a general architecture. Furthermore, Sockets allow the communication between co-operating processes to be realised either in stream or in structured (message oriented) mode. The stream mode could be employed by the database agent for communicating results back to the CGI processes (clients) on a character-by-character basis. This approach is expected to entail some noteworthy results in the response times of the system.
Further research in this area could include the determination of the optimum maximum size for system message queues. Such size should be properly adjusted to prevent the overflow of the memory structure (which leads to clients' crashes). As the maximum size of message queues is a kernel parameter, its modification requires kernel rebuild. The optimum size is strongly dependent on the size of the HTML page returned to the browser as well as the fragmentation level of responses generated by the database agent. Furthermore, the discussed size is a function of the dispatching capacity of the database agent.
| [1] | Berners-Lee T. and Cailliau R., World Wide Web Proposal for a HyperText Project, CERN European Laboratory for Particle Physics, Geneva CH, November (1990). |
| [2] | Berners-Lee T., Cailliau R., Luotonen A., Frystyk Nielsen H. and Secret A., The World-Wide Web, Communications of the ACM, 37(8) (1994). |
| [3] | Robinson D., The WWW Common Gateway Interface Version 1.1, Internet Draft, January (1996). |
| [4] | Everitt P., The ILU Requested: Object Services in HTTP Servers, W3C Informational Draft, March (1996). |
| [5] | Eichmann D., McGregor T. and Danley D., Integrating Structured Databases Into the Web: The MORE System, in the proceedings of the First International WWW Conference, Computer Networks and ISDN Systems 27(6) (1994). |
| [6] | Perrochon L., W3 "Middleware": Notion and Concepts, Workshop on Web Access to Legacy Data, Boston, MA, December (1995). |
| [7] | Eichmann D., Application Architectures for Web-Based Data Access, Workshop on Web Access to Legacy Data, Boston, MA, December (1995). |
| [8] | Microsoft dbWeb 1.1 Tutorial, Microsoft Corporation (1996). |
| [9] | WebDBC White Paper #1, A Quick Overview of the WebDBC 1.0 Architecture, Nomad Development Corporation (1995). |
| [10] | Hadjiefthymiades S. and Martakos D., A generic framework for the deployment of structured databases on the World Wide Web, in the proceedings of the Fifth International WWW Conference, Computer Networks and ISDN Systems 28(7-11) (1996). |
| [11] | Braek Rolv and Haugen Oystein, Engineering Real Time Systems, Prentice Hall (1993). |
| [12] | Crocker D.H., Standard for the Format of ARPA Internet Text Messages, STD11, RFC 822, UDEL, August (1982). |
| [13] | Stevens W.R., UNIX Network Programming, Prentice Hall (1990). |
| [14] | Date C.J., An Introduction to Database Systems, Addison-Wesley (1995). |
| [15] | Informix-ESQL/C Programmer's Manual, Informix Software Inc. (1996). |
| [16] | Ibe O.C., Choi H. and Trivedi K.S., Performance Evaluation of Client-Server Systems, IEEE Transactions on Parallel and Distributed Systems 4(11) (1993). |
| [17] | Perrochon L., Translation Servers: Gateways Between Stateless and Stateful Information Systems, Institut fur Informationssysteme, ETH Zurich, Technical Report 1994PA-nsc94 (1994). |
| [18] | Commer D.E. and Stevens D.L., Internetworking with TCP/IP, Vol. III, Client-Server Programming and Applications, Prentice Hall (1994). |