
Yoelle S. Maarek
Michal Jacovi, Menachem Shtalhaim
Sigalit Ur, Dror Zernik
IBM Haifa Research Laboratory
MATAM, Haifa 31905, ISRAEL
yoelle@haifa.vnet.ibm.com
Israel Z. Ben Shaul
Dept. of Electrical Engineering
Technion, Israel Institute of Technology
Haifa 32000, ISRAEL
issy@ee.technion.ac.il
Conventional information discovery tools can be classified as being either search oriented or browse oriented. In the context of the Web, search-oriented tools employ text-analysis techniques to find Web documents based on user-specified queries, whereas browse-oriented ones employ site mapping and visualization techniques to allow users to navigate through the Web. This paper presents a unique approach that tightly integrates searching and browsing in a manner that improves both paradigms. When browsing is the primary task, it enables semantic content-based tailoring of Web maps in both the generation and the visualization phases. When search is the primary task, it enables one to contextualize the results by augmenting them with the documents' neighborhoods. The approach is embodied in WebCutter, a client-server system fully integrated with Web software. WebCutter consists of a map generator running off a standard Web server and a map visualization client implemented as a Java applet runnable from any standard Web browser and requiring no installation or external plug-in application. WebCutter is in beta stage and is in the process of being integrated into the Lotus Domino.Applications product line.
The incredible size of the Web, coupled with its inherent lack of structure both at the inter- and intra- document levels, introduces great challenges for information discovery. To provide assistance in this daunting task, several approaches and corresponding tools have been proposed, mostly revolving around the two basic discovery paradigms --- searching and browsing.
The main limitation in most search engines and site mappers is that they are essentially search-only or browse-only, respectively. In other terms, they support one paradigm and effectively ignore the other. This approach introduces major scalability problems. At some point, information found by search engines becomes too big to be meaningful, due to the unrestricted global scope of the issued queries; and the generated maps tend to be too complicated due to lack of filtering or other content-based parametrization for both generation and visualization.
To address this limitation, several attempts were made to integrate browsing and searching. Some search engines, such as Yahoo, support search within a scope specified by a predefined browsing hierarchy. Other engines, such as WebGlimpse [Manber et al. 97], allow users to dynamically search the direct neighborhood of a visited page from within the Web browser. Other engines automatically create a browsing hierarchy from search results [Maarek 95], or at least a flat grouping for browsing, e.g., Excite.
Conversely, most site mapping tools provide primitive search facilities over the generated maps. Overall, however, most tools are either primarily search or primarily browse tools, with only simple cross-paradigm integration.
Our new approach, presented in this paper, does not make such a sharp distinction, and employs a tight and wide integration of searching and browsing, both in the underlying technology as well as in the overall purpose and functionality. The general idea is to integrate full-text search techniques inside the various functions of site mapping. This enables us to provide content-based tailoring of Web maps, not only in the visualization but also in the generation of the map itself. Moreover, the same tool can also serve for contextualized search, i.e., to find information along with its neighborhood, which may at times be as important as the found elements. So, depending on the user's goals, either browsing or searching or both can be employed. In short, our approach advocates the convergence of both paradigms in order to improve the overall support for information discovery.
The general approach of intertwining browsing and searching was embodied in the WebCutter system, presented in the rest of this paper. In Section 2, we outline the main concepts underlying WebCutter and its general functionality. In Section 3, we present WebCutter's unique and open architecture, which is by itself another important contribution of this work. Section 4 provides an operational view of WebCutter by walking through typical scenarios. Section 5 compares WebCutter to related work, and Section 6 summarizes the contributions of this paper.
WebCutter is both a mapping and a visualization tool, enabling users to create, maintain and view "Web maps", i.e., an organization of a set of nodes (URLs) and their interconnections (hyperlink references). This is in contrast with visualization-only tools that read a configuration file to construct a graphical view of a site but do not actually generate the maps. Furthermore, WebCutter is a dynamic site mapping tool, in the sense that the browse structure is automatically generated by a crawler that starts off from a set of initial "seed" URLs and constructs the map dynamically (although it is possible of course to create the map off-line, separately from the viewing phase). WebCutter's functionality rests mostly on two main powerful enabling technologies that set it apart from most other existing site mapping tools:
Based on these technologies, WebCutter provides several innovative features and properties, in addition to the conventional features found in most mapping tools.
WebCutter enables users to tailor, or "cut" the map according to the concepts they are interested in, expressed in natural language. Thus, instead of indiscriminately crawling through a large volume of hyperlinks, WebCutter "shapes" the map so at to explore more thoroughly in directions where relevant information is found. This is done by employing the "fish search" paradigm, [De Bra et al.], whereby each crawler agent explores "nutritious" areas which are likely to contain more "food", i.e. relevant documents, and neglects "dry" directions with no relevant findings.
A key aspect in determining areas with probable relevant information is the ability to evaluate and rank the relevance of documents. This is done by using a dedicated text-analysis component derived from the Guru full-text search engine. Guru applies a statistical information-retrieval approach and uses an original indexing unit based upon the notion of lexical affinities (i.e., multiple-word, co-occurrence based indexing units). The Guru system is discussed at length elsewhere [Maarek et al. 91], [Maarek 91].
Relevance information (or search information) is not used exclusively in the map construction stage, however. It is also used in the visualization stage to highlight documents differently according to their relevance to the user-specified interests. For example, Figure 1, shows a map of www.Lotus.com tailored to "Domino". Highlighting of relevant documents is done by coloring, i.e., the darker the shade of blue, the more relevant the document is. WebCutter thus employs similar but distinct usages of the user-specified tailoring information: one for affecting the generation of the map, and the other one for showing this information in context during visualization. These two phases are interleaved, though, as the user alternates between firing (incrementally) automatic exploration and manually selecting relevant nodes from which to continue exploration, recursively. In addition, users can exploit the highlighting by applying special operations that apply to (relevant) sub-maps. Both the issues of visualization and of subset selections are discussed later in this section.
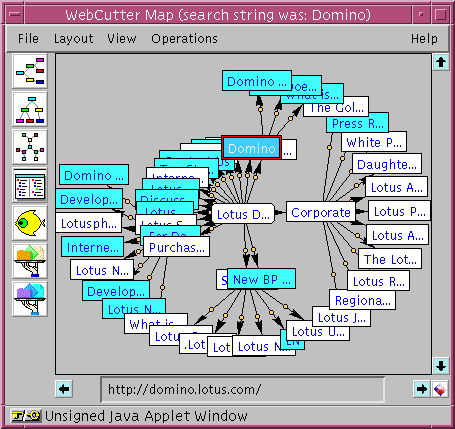
Figure 1. Star-like view.
Another important feature of WebCutter involves its multi-perspective visualization. WebCutter employs sophisticated layout algorithms [Rudich et al. 92] and multiple presentations of maps in 2D and 3D. Each of these presentations is designed to reflect different aspects and additional manipulations of the map. Examples of views provided by WebCutter are the traditional tree-control view, particularly useful for abstraction and ellipsis; a star-like layout (shown in Figure 1), useful for pursuing incremental exploration; and a fisheye view [Sarkar & Brown 92], shown in Figure 2., which enables users to focus on different regions of the graph. Additional content-based views can be provided as well: for example, we are constructing a view based on the conceptual similarity between documents, by utilizing a variant of Guru for finding the similarity between documents and using the clustering technology developed in [Maarek & Ben Shaul 96]. Some of the layout algorithms were specifically customized to site map visualization, while others used conventional techniques [Di Battista et al. 93]. Finally, each of the views can be further customized manually by the user, by allowing him/her to change the position of the nodes in the graph.
The screen dumps shown in this paper are in GIF format, but could be provided here as actual Java applets with which users could interact, provided that the paper be only read on-line rather than as a hardcopy. When a user clicks on a node, Webcutter reacts as following: (1) it shows its URL in the bottom of the applet, a la Netscape; (2) it expands its full-title (when in ellipsis form); and (3) it shows backlinks to other nodes (shown as blue arrows in color displays, or as gray arrows in monochrome hard copies of this paper), as shown in Figure 3. Clicking on the yellow spot on an edge makes the HREF label (i.e., the label that holds the document's URL, which is often different from the node's title) appear on the visual map. Double clicking on a node makes the page contents appear in the Web browser. Various other interactive features are available that are not discussed here for space reasons.
In order to ease navigation and manipulation of the graph, several "overviewing" tools were designed specifically for the WebCutter environment. These mini-maps (displayed as a small black square at the bottom left part of Figure 2) provide a high-level, condensed presentation of the map. By dragging the mouse in this mini-map, the user changes the point of view of the graph.
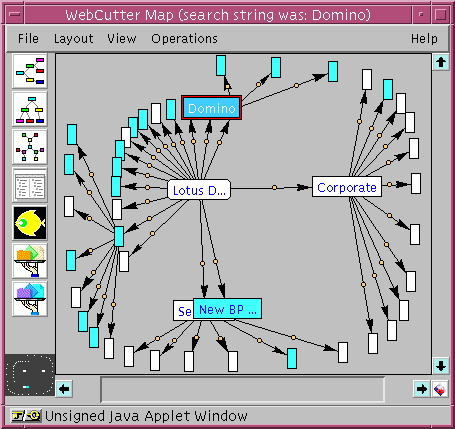
Figure 2. Fisheye view.
The interaction with the graph is based on the support for subgraph selection and group operations. This enables hiding nodes of lesser importance (for example, the set of nodes that could not be reached), hiding edges of lesser importance or redundant (backlink) edges, highlighting relevant nodes, and performing various operations on these groups as discussed below.
A prominent feature-set of WebCutter is the ability of selecting submaps based on graph topology, relevance to a topic, object type, etc. thereby providing an abstraction facility for group operations. Sample operations include:
Another interesting aspect of WebCutter concerns the intended use of the generated maps.
Long-term maps are those which are created with the intention to be used after their initial creation, perhaps by various users. Those persistent maps can thus be browsed, queried, refined, saved, and even edited. Furthermore, using different "interest" expressions, different maps derived from the same physical site(s) can be generated, each emphasizing different aspects of the site and hiding other aspects. This feature is particularly useful when different kinds of users are expected to browse the site. For example, a high-tech site may provide a "marketing-intensive" map for non-technical people, and a "technically-oriented" map for those interested in technical details. Such maps can be either tailored and prepared ahead by the Webmasters, or generated ad-hoc by knowledge engineers. Typically, the Webmaster builds or "cuts" in advance some subject-oriented maps to ease the browsing of his/her site. S/he might also use the map in a more traditional manner to detect broken links, gather statistical information, etc.
Another kind of useful maps are what we term "short-term" maps. By specifying a search query instead of an interest expression, WebCutter can be viewed as a dynamic search tool that returns its results in map form for contextualizing the results. The generated map is usually short-term, because its intended use is to augment the search.
The WebCutter system consists of two components:
Note that the WebCutter map will support the W3C site mapping protocol as soon as the latter is finalized. This effort at standardizing site map protocol has been initiated by Microsoft's Scott Berkun in the context of the W3 Consortium. Major players are involved in this effort (Microsoft, IBM, NetCarta, Apple, SoftQuad, etc.). The WebCutter team represents IBM in this effort.
Unlike other site mapping tools (e.g.,
NetCarta's WebMapper or InContext's WebAnalyzer as discussed in
detail in the Related Work section),
WebCutter-generated maps are not kept in a proprietary format that
requires an external viewer or plug-in. Instead, Webcutter maps are kept in
plain ASCII and viewed by a standard Java applet that gets automatically
downloaded by any standard browser, with no installation overhead.
This enables not only platform-independence but also full integration with
the Web browser. Users can view WebCutter maps and interact with them from
within their favorite Java-enabled browser (e.g., Netscape Navigator,
Microsoft Internet Explorer), as well as perform the usual surfing tasks
(view, save, print) from within the same application and same
user-interface: the browser.
Note that further communication between the applet and the Web
(for example, to perform incremental exploration) or the local
client (for instance, for saving maps locally) is also done via
invocation of CGI scripts on the same HTTP server because of
applets security restrictions. This may change when trusted applets are
made available.
WebCutter enforces a decoupling between view and model, which is highly recommended in most graph visualization works. The dedicated crawler generates the map model as a graph, and the applet is exclusively responsible for visualizing that graph in various alternative views. This decoupling fits naturally with a client/server architecture, and presents multiple advantages:
The WebCutter system has been fully implemented and is in beta stage. It is currently available from within the IBM firewall. The server has been implemented in ANSI C, and runs on AIX 4.1 and Windows NT, and is in the process of being ported to Sun Solaris and HP/UX. It comes with a set of CGI scripts and forms, as an add-on to regular HTTP servers (Apache, NCSA) as well as Lotus Domino. The client part, i.e., the visualization applet, comes as a set of Java classes that is stored on the HTTP server or locally on the client to work in disconnected mode.
WebCutter is in the process of being ported and integrated into Lotus Domino.Applications product line.
We present two scenarios that demonstrate both uses of WebCutter. The first "search-oriented" scenraio gives the perspective of the end user who wants to discover information and builds dynamically a short-term map for this purpose. The second "browse-oriented" use exemplifies the case of a Webmaster who wants to manage his/her site (check for broken links for instance) as well as to build in advance ("pre-cut") long-term maps for specific groups of users or communities of interests.
In this example, the user, Frank, is trying to find out what his former officemate in Grad School is doing these days. Frank knows that his friend, David, is working at Microsoft Research, but nothing more. So Frank accesses a WebCutter site, fills out an HTML form asking for a "tailored map", and indicating what site to explore, how long he is ready to wait, how big a map he wants, and his search string. After his request is issued, a tailored map pops up with relevant pages highlighted in blue, as shown in Figure 3. At the first level of the exploration tree, WebCutter discovered one relevant page, and automatically pursued in that direction to find more relevant information, it thus discovered not only the home page of his friend (entitled "David K." here) but also in which group he works (Frank clicked on it to get the full title of the department.) If Frank wanted more information, he could pursue the dedicated exploration from that point and incrementally discover relevant pages and links (nodes and edges) to be added to the map.
In real life, Frank first used the local search service at Microsoft Research (based on WAIS), but he got very bizarre results on that very day probably because of a temporary bug. By using WebCutter here, Frank not only finds a way to discover information on a site on which the search service is "out-of-order", but he gets at one glance both search results and contextual information. He is also guaranteed that every page identified is available at the very moment the map is generated, which is not necessarily the case with prebuilt search databases.
In this example, the Webmaster of www.Lotus.com wants to attract the attention of visitors to the recent Domino efforts. He builds a large long-term map of his site tailored to "Domino", as shown in Figure 1.
As might be expected, the Domino site is the one that gets the darkest shade of blue, i.e., it is regarded as the most relevant document, but other related pages on the Lotus site itself are shown too (with a lighter shade). So the map provides a subject-map across sites boundaries. The Webmaster can simply store the map on his site and have interested users either use it for browsing, or as a basis for pursing exploration incrementally from one node or another.
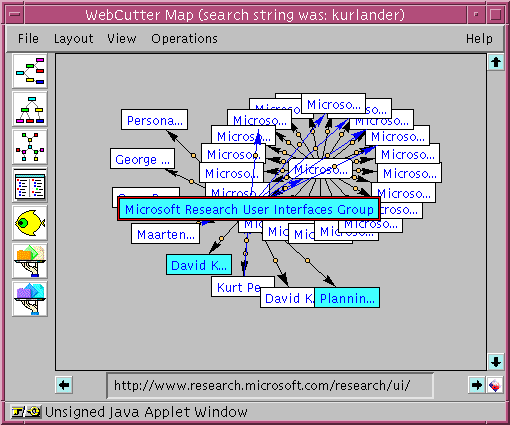
Figure 3. Short-term Map.
As can be seen from the above list, there is an increasing number of site mapping tools available for end-users for browsing and discovery purposes as well as for Webmasters for site management purposes. All of these tools, however, provide exclusively structural Web maps as identified by a crawler. They apply mainly the browsing paradigm and exploit the search paradigm only minimally. In particular, none of these tools provide user-customizable maps that take into account the user's interests. The only tool we found that provides more contents-based maps is Visual Site Map Research Prototype from the University of Kentucky which automatically organizes the site by using a neural network system. However, because of the high computation cost of neural network training, maps cannot be generated on the fly. The organization is done off-line after the map has been generated.
In this paper, we have presented WebCutter, a system for dynamically generating tailored Web maps. The interesting and unique aspect of WebCutter is the weaving of search and browsing technologies, which is reflected in many of its features. The idea is to utilize the "semantics" of the documents as drawn by the text-analysis component, to form the tailored visual representations. This is in contrast with most conventional mappers, which rely only on the "syntax" of the documents set, i.e., the physical structure of the nodes and links. In addition, WebCutter is a client/server system integrable into complete Web site management solutions. It supports sub-maps selection, map management and open standards. In particular, maps are viewed by Java applets, and are fully integrated with the Web-browser.
Thanks to Frank Smadja for playing the role of the average end-user and to David Kurlander for being the involuntary object of our experimental (but real!) search scenario. Our students, Yohai Makbily and Ethy Benaiche helped on the implementation of some of the WebCutter visualization features, and Daniel Rozenshein participated actively in the testing stage.
We wish to thank Ron Fagin for his emergency reviewing. We also wish to thank the supporters of WebCutter at the IBM Internet Division (Lisa Morley), at Lotus (Keith McCall) and at the IBM Research Division (Stu Feldman, Yoav Medan, Pnina Vortman) who are helping making a product out of what was a mere research idea only a year ago.
Note: Product and company names herein may be trademarks of their respective owners.