
Masaaki Nabeshima
NTT Software Laboratories
3-9-11 Midori-cho, Musashino-shi, Tokyo, Japan
nabe@slab.ntt.co.jp
This paper proposes the concept of a domain cache, which is dedicated to handling access to a particular domain name, and reports experiments in the Japan Cache Project which operates a public cache server for access to JP (Japan) domain Web servers. The goal of this project is to spread information about Japan to North America. This project included some experiments in prefetching information to makes use of less crowded access times, maintaining the coherence between the cache server and primary servers by primary server refresh, and operating a cache replication server, which keeps the primary server information in the cache and functions not as a proxy server but as an HTTP server.
The high cache:hit ratio obtained suggests that domain caching is an effective cache server operation method. However, we could not perform effective prefetching because of the difficulty in predicting user accesses. Coherence-maintaining and cache-replication server mechanisms were created. We appeal for cooperation from servers in Japan.
Keywords: World Wide Web, Cache Server, Domain, Prefetch, Coherence
Caching technology is a good way to improve access speed to online information on the World Wide Web (WWW). If the information is retrieved from a nearby cache server, it shortens the access route to the information and reduces the latency. It also minimizes duplicated access to the same information and reduces the load on the primary servers and improves the server response.
Due to the potential effectiveness of cache technology, most current client software has a local cache mechanism, and there are a lot of cache servers operating at each site. Although some global caching projects are running, there seems to be a lot of room for improvement at the present time. Therefore we must establish a more effective cache server operation methodology.
In section 2 we propose the basic concepts of the domain cache. In section 3 we describe the Japan Cache Project and introduce three new experiments: Prefetching, Primary Server Refresh, and Cache Replication Server. In section 4 we describe the system used in this project and in section 5 we discuss the results of the experiments. Finally, in section 6 we mention the future of this project and draw conclusions.
There are a lot of cache servers at each site. It is a good way to suppress the same access from users at the site. Frequently accessed information from users at a site is stored in the cache and the information is retrieved from the cache so that the users can reduce the latency of retrieval. However, infrequently accessed information may not be stored in the cache in advance and information stored as a result of access by one user, may not be retrieved afterwards by other users. These minor information accesses, however, may be spread throughout other sites and stored in cache servers at other sites. If we can gather such minor information into one cache, we can get a higher hit ratio.
With regards to global cache servers, whose purpose is to gather the accesses from other cache servers, if the global cache server has a large enough cache space to keep the minor information in the cache for a long enough period of time, users can retrieve the minor access information from it. But in reality, this information often expires sooner due to the limited cache space. Therefore the hit ratio stays low.
In other words, to get a high effectiveness from the cache server, the tendency of access should be narrowed. Ideally, it is best to gather similar kinds of access in a particular cache server. For example, having a cache server for movie related information or one for jazz related information.
Japan Cache Project[1] was motivated by the Japan Window Project[2] [7], which aims to disseminate information about Japan to users outside Japan. In that project, information is selected and edited to allow users access to compiled information in a timely and useful manner. The goal of the Japan Cache Project, on the other hand, is to create more convenient access to raw Japanese information found on the Web.
To achieve this goal, we decided to operate a public cache server in the USA, for access to Japanese information, and opened it to the public on April 1st, 1996. Our final goal for this cache server is to fill it with information related to Japan. Currently, there is no efficient method to gather only the accesses containing information related to Japan. In other words, tagged information is required for this purpose, and currently this is not available. Therefore, the Japan Cache server is dedicated to accesses to JP (Japan) domain servers at this time (Figure 1).
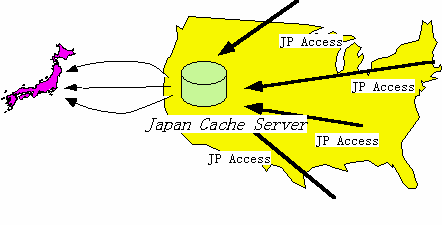
At present, some countries have national cache servers located in their own territory to accept accesses to their country domain from other countries. However our cache server is located not in Japan, but in North America, in order to serve users in North America. This offers the following advantages.
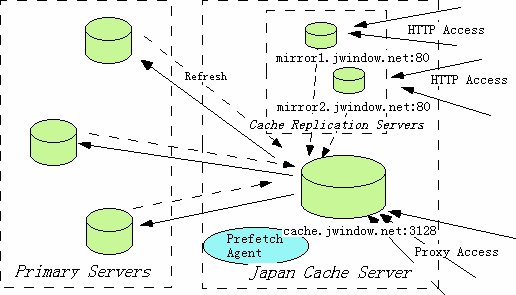
We made three new experiments: Prefetching, Primary Server Refresh, and Cache Replication Server. Overall image is shown in Figure 2.
There are certain times when access to JP domain servers is easy. For Japan, we thought that the early morning would be the best time to access Web servers. This is a good time to store information that will be accessed by users later. To confirm this common view, we analyzed the cache server access log which indicates the size of data transferred and the time taken.
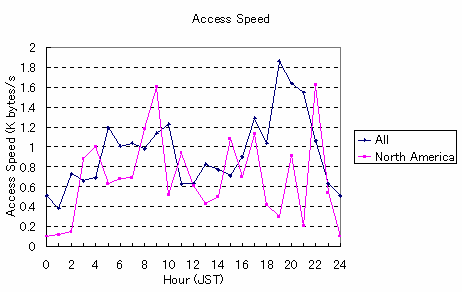
In Graph 1, the average access speed from all users reveals the tendency of the network and server congestion in Japan. This confirms the common view that servers are hard to access around midnight and lunch time. Midnight congestion is caused by the telephone tariff bands, which offer a flat telephone rate service between 11 PM to 8 AM, so many private users access the Web servers before going to sleep. Lunch time congestion is caused by a lot of business users accessing Web servers during their lunch break.
This data also shows that access is faster in the evening than early morning. This is contrary to the common view in Japan that the best access hours are in the early morning. We thought one reason might be that the access is affected by the speed between the cache server and the users. Therefore we studied accesses from North America in order to see access speeds without having to consider the speed delays caused by lines which continue out of North America. This confirmed that early morning is the best access time.
There are many users who cannot use the Japan Cache server. At some sites, users have to access outside of the site through a firewall proxy server for security reasons. They can not use any other proxy server. Another reason is client software limitation. In this case, the Japan Cache server only permits accesses for the JP domain servers, so client software must have a domain name base proxy selection mechanism. Currently this is supported only by Netscape Navigator.
To accept accesses from these users, we must select an operating cache replication server that is not a proxy server. To the user, it appears to be a type of mirror server, in which all information is replicated from the primary server. In this case, the information is retrieved from the primary server through the cache and frequently accessed information is stored in it. Thus one cache replication server is required for each primary server. Thus we operate several cache replication servers for the primary servers that are popular with users.
The Japan Cache server is a SUN Sparc Station-20 with 128 MB of memory and 8 GB of cache space. This is at NTT Multimedia Communication Laboratories in Palo Alto, California and is connected to BBNPLANET Stanford NOC via a T1 line. The USA ends of many of the international links between USA and Japan are located on the west side of the USA, an area through which a lot of the traffic to Japan passes. Therefore it is ideal in terms of network topology.
We initially selected the harvest object cache as the cache server software, but we switched over to the Squid Internet object cache [4], a successor to harvest, after its release, because the development of harvest in academic circles was suspended.
The Squid has an inter cache server protocol (ICP) and allows communication between servers. There are two types of relationships between servers.
The information on the cache is a replication of the original information on the primary server, so some information may not be coherent with the original. In Squid, coherence is kept based on a Time-To-Live (TTL) expiration model. A TTL is assigned to an object when it enters the cache. The object is deleted at the end of the TTL. The TTL is calculated in two ways.
The Japan Cache server accesses two cache servers in Japan as siblings: cache.imnet.ad.jp, operated by NTT Software Laboratories on the Inter-Ministry Research Information Network and japan.park.org, operated by the WIDE Project on the Internet 1996 World Exposition JAPAN Network.
TTL settings are shown in Table 1. The settings of some of the most popular information, which is determined by the access log, can be altered by an administrator. This is based on the frequency of changes. The setting for information that is changed every day, like a newspaper, is shorter than the default setting. The setting for information that is changed weekly on the regular update-time, like a magazine, uses only a fixed TTL, because it is easy to distinguish whether the information stored in the cache is stale or fresh.
| 1) Age percentage TTL (Maximum) | 2) Fixed TTL | |
| Default | 60% (60 days) | 60 days |
| Daily | 20% (2 days) | 2 days |
| Weekly | - | 7 days |
The prefetch software is based on WebCopy[8]. It is an extended version to avoid explosions of prefetching accesses. Currently it does not support the standard for excluding software robots. It has three restrictions:
Target information for prefetching is classified into two types. One is the top 100 most-frequently accessed pages. These are selected by access log from the past one week. The other is from current events and newly submitted information (what's new). The newly submitted information is taken from the what's new pages at www.ntt.co.jp [6]. These pages are one of the most popular what's-new-pages in Japan. The Internet Watch [5], being an email newspaper, has many subscribers in Japan. This newspaper is the source for current events.
The prefetching area is 2 levels deep and 20 levels wide. A two-level depth refers to files reached by following two sequential links the original URL list. When referring to a 20 level-width, we refer to the number of links from a file being limited to 20.
Newly submitted pages may have been recently updated. These pages may expire soon due to the Squid cache server expiration policy. This expiration policy takes into account that newly updated pages tend to be updated quickly. For this reason, we set up a cache server for prefetched information. The TTL for information stored in this cache is set to 3 days. The main cache server treats this cache server holding prefetched information as a sibling server. This allows us to monitor the usage of the information more easily. However we cannot use this method for frequently accessed information, since it includes news information, which is frequently changed and expires quickly on the main cache. After it has expired, only stale information can be found on the prefetched server. For this reason, we placed this type of frequently accessed information directly on the main server. This is also why we did not collect the usage information for this type of frequently accessed information at this time.
So far, the refresh notification mechanism is based on email. When information on the primary server is updated, a notification is sent out to the Japan Cache Server by email listing stale URLs. At our cache server, an email daemon program invokes the refresh program. This refreshes the stale information in the cache. Currently, only www.ntt.co.jp sends this notification. The mechanism for the notification is: this Web server has a working server which pushes out the new information to the public server via a mirror program. At this time, the mirror program sends a transmission log to the administrator. This invokes a program which translates the mirror log into a URL list for refresh and sends the list to the Japan Cache server.
As a cache replication server, we operate the Squid Internet Object Cache in HTTP accelerate mode. The Squid in this mode works the same way as a cache replication server. This mode was originally intended to make use of Squid's high-speed HTTP access processing mechanism. In brief, it operates on the same LAN in which the primary server is working, accepts the access instead of the primary server, and stores the information in its cache (frequently accessed information is stored in the main memory) to improve the response. As an experiment, www-ntt.nttam.com (in California), whose primary server is www.ntt.co.jp (in Tokyo), is in operation.
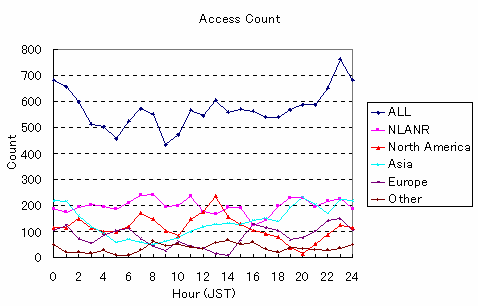
This data was collected from October 1st 1996 to October 30th 1996. The grouping of the regions in this data was based on domain name. The version of Squid was 1.0.18.
Also, 13% (5% for cache.imnet.ad.jp, 8% for japan.park.org) of missed TCP accesses achieved hits on the sibling caches. Combining the results for the Japan Cache server and the two sibling servers shows that we achieved a hit ratio of around 60%.
Regarding the prefetching of frequently accessed information selected from the access log, 81% of the information already existed in the main cache. Therefore, this experiment leads us to believe that prefetching of frequently accessed information was insignificant.
| ML* subscriber | Servers | Server access ratio | Clients | Client access ratio | |
| North America (NLANR) | 247 (-) | 4 (1) | 59% (56%) | 412 (-) | 54% (-) |
| Asia (Japan) | 135(95) | 4 (0) | 27% (0%) | 255 (113) | 17% (8%) |
| Europe | 39 | 8 | 13% | 89 | 13% |
| Others | 22 | - | - | 1 | 0% |
| Not named | - | 4 | 0% | 128 | 15% |
| One month total | One day average | ||
| TCP access | Total | 425,574 | 14,185 |
| Servers | 255,191 (60%) | 8,506 | |
| Clients | 170,383 (40%) | 5,679 | |
| ICP access | Total | 727,833 | 24,261 |
| Hit ratio | |
| ICP | 58% (HIT: 18%, HIT_OBJ: 40%) |
| TCP | 33% (Server: 25%, Client: 56%) |
| Prefetched information | Ratio of newly got information | Prefetched Information Usage | |
| Frequently accessed information | 3241 files | 19% | - |
| Internet Watch | 1315 files | 75% | 14% |
| NTT WHATSNEW | 2543 files | 84% | 8% |
So far, we have put the domain cache into practice as a designated cache server for access to specific domain name. This kept the hit ratio higher than usual cache servers and helped to show the effectiveness of the domain cache concept. In the future, we hope to establish a mechanism for an actual domain cache server utilizing different kinds of information.
Currently, two cache servers in Japan cooperate with this project as sibling servers. We are asking for cooperation from other cache servers in Japan to act as sibling servers. We also plan to establish a better access method for these servers, not just a simple sibling server relationship. As an example, there are some primary servers that can be accessed faster by taking a detour through a particular cache server to avoid heavily congested areas.
With regards to keeping coherence and operation of the cache replication server, we have set up the system. At present, we are asking for cooperation from the primary servers in Japan. Also, under the current system, even if the information is kept coherent, the cache server receives coherence check requests like an If-Modified-Since request and sends inquiries to the primary server. We will need to improve the cache server to block these requests.
We will analyze the effectiveness of prefetching in detail and then establish a method for predicting user access for effective prefetching. Accordingly, we must start by analyzing the access tendency in detail from the access log in order to establish the prediction method.
Most of this work was done at NTT Software Laboratories Palo Alto, which is one of the predecessors of NTT Multimedia Communication Laboratories (NTTMCL), when I worked there. This project is now under NTT Software Laboratories and NTTMCL.
I thank Atsuhiro Goto, Burton Lee, and the members of the Japan Window Project, who gave me the opportunity to start this project. I thank Kathryn Kada for helping me write this paper in English. And I thank Hirohide Mikami and the members of the global software design group, who have been a great support from Japan.
[1] "Japan Cache Project Home Page", http://cache.jwindow.net/
[2] "Japan Window Home Page", http://www.jwindow.net/
[3] "NLANR Caching Project", http://www.nlanr.net/Cache/
[4] "Squid Internet Object Cache", http://squid.nlanr.net/Squid/
[5] "Internet Watch", http://www.watch.impress.co.jp/internet/index.htm
[6] "What's New in Japan", http://www.ntt.co.jp/WHATSNEW/
[7] Burton H. Lee, Atsuhiro Goto, Michael L. Bayle, Yasuhisa Sakamoto, Jeremy Thibeaux, "Japan Window: A US-Japan Internet/WWW Collaboration for Japanese Information", INET'95 Conference, June 27-30 1995
[8]Víctor Parada, "WebCopy Documentation", May 31 1995
[9] Michael L. Kazar, "Synchronization and Caching Issues in the Andrew File System", USENIX Conference Proceedings 1988, pp. 27-36.