
Richard M. Keller*, Shawn R. Wolfe**, James R. Chen***,
Joshua L. Rabinowitz**, and Nathalie Mathe***
Computational Sciences Division
NASA Ames Research Center
Moffett Field, CA 94035-1000
keller@ptolemy.arc.nasa.gov
Affiliations: NASA*, Caelum Research Corp.**, Recom Technologies, Inc.***
Web browser bookmarking facilities predominate as the method of choice for managing URLs. In this paper, we describe some deficiencies of current bookmarking schemes, and examine an alternative to current approaches. We present WebTagger(TM), an implemented prototype of a personal bookmarking service that provides both individuals and groups with a customizable means of organizing and accessing Web-based information resources. In addition, the service enables users to supply feedback on the utility of these resources relative to their information needs, and provides dynamically updated ranking of resources based on incremental user feedback. Individuals may access the service from anywhere on the Internet, and require no special software. This service greatly simplifies the process of sharing URLs within groups, in comparison with manual methods involving e-mail. The underlying bookmark organization scheme is more natural and flexible than current hierarchical schemes supported by the major Web browsers, and enables rapid access to stored bookmarks.
The World Wide Web has made a wealth of information resources available for direct and easy access on the user's desktop. However, the availability of such great quantities of information has left some users bewildered and overwhelmed. Finding appropriate information on the Web is a significant problem in itself, but once the information is found, a secondary problem surfaces. The uniform resource locators (URLs) associated with the found information must be organized and stored in a manner that enables rapid and effective access for individuals and groups. In this paper, we focus on this problem of personal information organization and access, and present an approach to organizing and managing URLs.
Web browser bookmarks (also known as "hotlists" or "favorites") predominate as the current approach to managing URLs. Depending on the sophistication of the browser's bookmarking facility, users can store URLs in either flat lists or hierarchical folder structures for subsequent reference. Hierarchical bookmarking schemes represent the state of the art in the most widely-available Web browsers, including Netscape Navigator and Microsoft Internet Explorer. Yet these bookmarking schemes exhibit some significant deficiencies that hinder effective organization and access to URLs:
Although clearly superior to unstructured lists, the widely used hierarchical folder organization forces users to think in terms of a neatly decomposable structure consisting of disjointed clusters of related URLs. However, a single piece of information is often relevant in multiple ways, and thus is not easily categorized within a single folder. For example, a single Web page describing restaurants in San Francisco may be useful in a variety of different circumstances, and should be accessible by a number of different categories: restaurants, San Francisco, cooking, Web page design (in case the page had a particularly interesting design), HTML hacks (in case the HTML for this page used some interesting techniques), entertainment, etc. Although some browsers permit users to insert a single bookmark into multiple folders by creating copies or aliases, this scheme requires tedious replication and manipulation. Furthermore, the hierarchical folder interface makes it difficult to see cross-connections among aliased URLs. More generally, the hierarchical bookmark organization biases users toward storing information resources in disjoint, decomposable clusters -- even when the information does not actually fit this pattern. When it comes time to retrieve a relevant URL, the predefined hierarchical structure may not be appropriate for the current task or context. We conjecture that no single static structure will be appropriate in all contexts.
The desire to share Web resources among groups of people with related interests is significant and growing. Yet current browser bookmarking schemes are oriented toward a single user, and provide few facilities for sharing URLs within a workgroup. When a user wishes to share a particular URL with colleagues, s/he must manually e-mail that URL to the workgroup, and then colleagues must add it to their bookmark list. As this process is not integrated with browser functionality, this is a particularly awkward and inconvenient method of collaboration. To share an entire set of bookmarks among colleagues, the user may send the bookmarks via email and then use the browser's "import bookmarks" feature. However, new bookmarks must be manually merged into the user's existing folder structure after importing. The overhead associated with these manual bookmark-sharing methods is significant enough to discourage their use on a regular basis. Moreover, these manual methods provide no computational infrastructure support for managing bookmark collections within workgroups.
For folders with large numbers of URLs, finding the most useful information often involves scanning a long list of URLs. Ordering URLs based on previous experience can facilitate rapid location of high-quality information. Typically, a small subset of URLs is referenced frequently, and these URLs should be prominent and visible within the organizational structure. With current Web browsers, the presentation order for URLs within a bookmark folder is determined by initial user placement. After some experience, the user will find that certain URLs prove to be more useful and relevant than others. To incorporate this experience into the folder structure, the user must continually rearrange the folder ordering to keep useful URLs near the top of the list. In workgroup situations, determining which URLs are most useful for the group at large is difficult, at best. Yet bookmark presentation order is even more important for structuring workgroup collections than for individual collections. Workgroup collections tend to grow rapidly as a function of workgroup size, and users can become overwhelmed with information without some organizational mechanisms, such as utility ordering.
With hierarchical schemes, navigational access to information can be tedious and frustrating when information is nested several layers deep. Embedded folders are either hidden from the user's view or obscured by clutter in folder-tree displays. Viewing URLs contained within multiple folders simultaneously involves navigating the tree-structure at multiple levels and consolidating the results within a single view. Current browsers provide little support for this type of functionality.
To address the above concerns, we have implemented a prototype system, called WebTagger, that provides an alternative to current browser bookmarking schemes. Our intent in building this prototype was to develop a test bed for future research in personal information organization and collaborative information access. The storage and access mechanisms employed in this prototype have been developed as part of our research on adaptive indexing algorithms for hypertext [Mathe & Chen 96]. This indexing mechanism has also been successfully integrated into Adaptive HyperMan, a sophisticated hypertext viewer used by Space Shuttle flight controllers at NASA Johnson Space Center [Rabinowitz et al. 96].
The paper is organized as follows: Section 2 describes the basic functionality of the prototype, and Section 3 describes its basic underlying storage and access mechanisms. Section 4 reviews design and implementation decisions faced in developing our prototype. Section 5 discusses related research, and Section 6 concludes.
WebTagger is a prototype bookmarking service that enables authorized users to store, organize, access, and evaluate URLs -- either individually or within a group structure. Each WebTagger user is assigned a personal memory -- a repository in which to store and organize URLs. In addition, users can be optionally assigned access to one or more group memories for use by groups of individuals who wish to share URLs relevant to topics of mutual interest. Each authorized member of a group can deposit or view URLs in the associated group memory. When a user adds a new URL to a memory, the user must classify it in terms of one or more topical categories. These categories are initially established by the user -- either manually or by automatically importing folder names from a Netscape Navigator bookmark file. The categories associated with a memory may be subsequently augmented or modified as necessary. For group memories, entire group has responsibility augmenting and maintaining the list of established categories. Users can retrieve URLs by querying their memories using categories as search indices. WebTagger provides a utility-ranked listing of all URLs that match the user's query, and allows the user to supply feedback as to which URLs on the list are useful in relation to their information needs. In response to this feedback, WebTagger modifies the ranking of those URLs during subsequent retrievals.
WebTagger is implemented as a proxy-based system. Users configure their Web browsers to use the WebTagger proxy, which intercepts each standard (i.e., not programmatically-generated) Web page served to the browser and inserts a set of interface buttons at the top of the page (Figure 1). The proxy approach enables users to access WebTagger without installation of plug-ins or special browsers. When a user accesses WebTagger via one of the interface buttons, a user identification and authentication process is initiated. The interface buttons provide users access to the system's various functions, including categorizing, retrieving, importing bookmarks, and viewing the entire contents of a bookmark memory. In the following subsections, we describe the basic system functionality from the user's perspective; the underlying indexing and access mechanisms are described in Section 3.
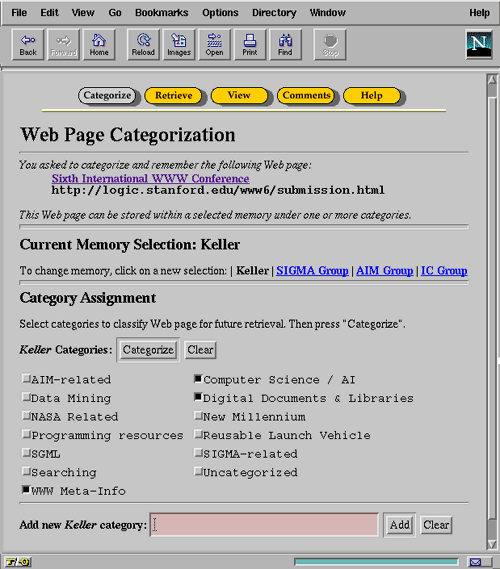
To bookmark a particular Web page, the user clicks the CATEGORIZE button that WebTagger's proxy has inserted at the top of the page. In response, the user is presented with a form listing a set of categories under which the page may be classified (Figure 2). A different set of categories is associated with each memory in the system; the displayed categories reflect the interests of the individual or group associated with the currently selected memory. (Initially, the selected memory is set to the user's personal memory, but this can be changed by choosing another memory on the form.) The categories associated with the selected memory have been previously established -- either by manual entry using the field at the bottom of the form, or by automated processing of a Netscape Navigator bookmarks file. On the form, the user simply checks off the specific categories relevant to this page and clicks the CATEGORIZE button. In the Figure, the user has classified the WWW6 Conference page under three separate categories: WWW Meta-Info, Computer Science/AI, and Digital Documents & Libraries. WebTagger associates these three categories with the WWW6 URL, and stores the URL within the currently selected memory for subsequent retrieval. Using the form, the WWW6 URL could be added to any of the group memories listed by clicking on a new memory selection.
To retrieve URLs, the user clicks the RETRIEVE button and fills out a form similar to the Categorize form shown in Figure 2. The user selects a subset of the categories established for the current memory, and these are used as a retrieval index into the memory. WebTagger provides two different retrieval modes: disjunctive or conjunctive. These are discussed further in Section 3.
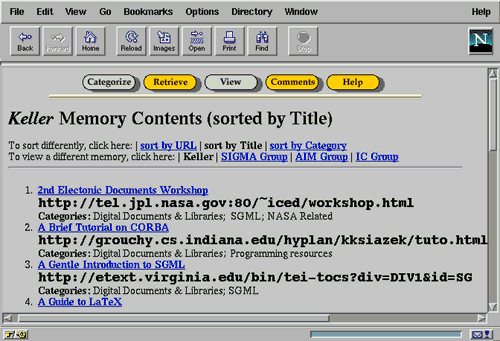
Figure 3 presents the results of a retrieval from the user's personal memory with the two selection categories WWW Meta-Info and Digital Documents & Libraries. Returned results are ordered based on previous user feedback, from most useful to least useful. Next to each retrieved URL is a set of radio buttons that optionally enable the user to provide positive or negative feedback on the relevance of the returned URL to the user's task. User's may provide feedback on multiple URLs at once. If the user provides feedback, WebTagger processes the feedback and presents a reordered list of retrieval results. Items that received negative feedback will move down the list, and items that were favorably reviewed will move up. The specific details of algorithms used to process feedback and order results are presented in [Mathe & Chen 96].

Users can view a listing of the entire contents of a memory sorted in three different ways: by title, by URL, and by category. In the title and URL listings, the stored categories are reported for each item. A sample of the title-sorted format is given in Figure 4.
To facilitate transition from Netscape Navigator's bookmarking scheme, our system can parse a Navigator bookmark file and create a corresponding WebTagger memory initialized with the set of bookmarks in that file. The system also uses the names of the hierarchical bookmark folders to establish an initial set of categories for the memory. Each bookmarked URL is automatically classified under a set of categories corresponding to the URL's containing folders in the original bookmark folder hierarchy.
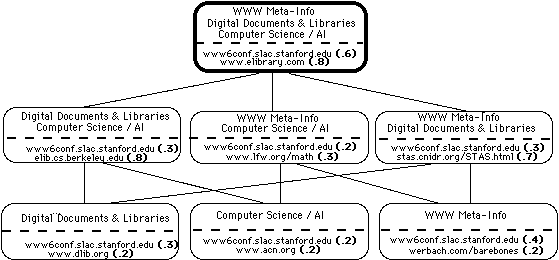
The adaptive bookmarking mechanisms of WebTagger are enabled by a novel storage and indexing scheme. Bookmarks for each memory are stored within a sparse lattice structure in which each node represents some combination of categories defined for the memory. Figure 5 illustrates the part of the lattice structure that stores the WWW6 Web page used in the example in Section 2. Associated with each node is a list of URLs and associated weights between zero and one representing their utility in terms of the user's information needs. When a user categorizes a new Web page, its URL is logically stored in a node corresponding to the exact combination of categories selected by the user, and also in all nodes corresponding to subsets. (In the figure, note that the WWW6 URL is stored in seven different nodes.) The weight associated with a new URL varies according to the node in which it is stored. In the node matching the exact combination of categories, the URL is assigned a neutral utility weighting (.5). In subset nodes, the URL is assigned a lesser, or discounted weighting. This weighting scheme assumes the URL will be most useful when retrieved in the context of the exact set of categories selected by the user, but may also be useful to a lesser extent when a subset of those categories is used for retrieval. When a user provides feedback on a URL, the weights for that URL are adjusted upward or downward, depending on whether feedback is positive or negative. The node with the exact combination of categories used for retrieval receives the strongest feedback, and subsets receive less feedback in proportion to their lattice distance from the exact node. To control combinatorics, nodes in the lattice structure are purged by a genetic algorthm when their frequency of access drops below a specified threshold.
During retrieval, WebTagger fetches URLs from those nodes in the lattice structure that are deemed relevant based on the user's retrieval categories and retrieval mode. In conjunctive retrieval, WebTagger retrieves all URLs stored in the node corresponding the exact combination of retrieval categories -- assuming the node for this combination exists in the sparse lattice structure. Otherwise, the system retrieves URLs from all subset nodes one step distant from this position in the sparse lattice. In disjunctive retrieval, WebTagger retrieves only the singleton subsets corresponding to the individual categories. Once the URLs are retrieved from the relevant nodes, they are merged, sorted, and thresholded so that URLs with extremely low utility are pruned prior to display for the user.
One of the main advantages of this representation scheme is its specificity and fine granularity for the purposes of registering feedback on utility. Each node storing a given URL within the lattice structure represents a different retrieval context. A node that is useful in one retrieval context may not be useful in others -- even if the associated categories are similar. In other words, in some cases the utility of a URL may not degrade uniformly in proportion to the distance from the original category combination. The lattice structure allows this type of nonlinear "exception behavior" to be captured. Full details of the representation scheme and its motivation can be found in [Mathe & Chen 96].
The WebTagger bookmarking service addresses the main deficiencies we cite for current browser bookmarking schemes. The system provides a simple means of organizing and sharing bookmarks using a structure-neutral categorization scheme, rather than a hierarchical filing scheme. The neutrality of this bookmarking scheme allows users to concentrate on tagging URLs with the most appropriate categories to facilitate subsequent retrieval, rather than forcing users to select a single best location within a rigid hierarchical structure. Retrieval is simple and quick, and requires no elaborate navigation through complex folder structures. To facilitate rapid access to useful information, WebTagger automatically ranks retrieved URLs according to users' previous reporting of utility. The utility rankings are continuously refined as more feedback is received from users. The uniform interface employed with either personal or group memories reduces the user's cognitive load and greatly simplifies the process of sharing URLs when compared with manual methods employing email. Members of groups sharing bookmarks may be located anywhere over the Internet, and are not limited by platform, location, or proprietary software.
In the balance of this section, we evaluate some of the design and implementation decisions associated with the development of WebTagger, and review some of the current implementation's strengths and weaknesses. These observations are based on limited testing within our own development group; we have recently completed beta testing with a larger group of users and are in the process of analyzing these results.
Our decision to implement WebTagger as a proxy-based service ensures universal access without the need for additional browser software. However, there are several trade offs involved in making this decision. Use of a proxy can slow down Web page delivery, and WebTagger users may notice some degradation in service. Users may also find WebTagger somewhat intrusive, as the system prepends buttons to each page served (Figure 1). Modification of the actual browser interface might be a better solution, but would require more development and installation overhead and would compromise universal delivery. We are considering various methods of addressing these concerns.
WebTagger is quite easy to use, but still requires the user to manually categorize new URLs according to the established set of categories prior to storing it. We are planning to implement an automatic categorization feature to aid in this process. WebTagger would perform text analysis [Lewis & Hayes 94] on a Web page to select a plausible subset of existing categories for classification. Users could choose to either review the auto-generated category selections or accept them without review.
A number of special considerations must be addressed in conjunction with the formation of collaborative URL repositories, including moderation, awareness, and feedback. Currently, WebTagger supports only unmoderated group interaction. All group members have equal power and responsibility in managing the group memory, including controlling the set of categories, the memory contents, and the group membership. However, for large groups, a moderator may be desirable to provide centralized control of access and management functions. For example, a moderator might control the establishment and modification of categories, and monitor the appropriateness of new URLs added to the memory.
A second consideration in establishing group memories is the user's awareness of other group member's changes to group memory. In the current system, awareness is quite limited. Users see additional URLs added by other members only if they issue a retrieval request that covers the new items, or view the entire memory contents. We are evaluating alternative notification schemes, including e-mail and on-demand notification facilities.
A third consideration for collaborative repositories is the affect of multi-user feedback on the utility rankings of retrieved URLs. The success of the utility feedback mechanism in group settings depends on the consistency of utility ranking across members of the group. If the group is cohesive and is performing similar tasks, then the intergroup ranking consistency is likely to be high. Users will likely find similar information useful and relevant under these cohesive circumstances. The more divergent the interests and tasks associated with the group members, the less consistency one would expect to observe in the utility rankings. In practice, this means that we would expect to see relatively stable rankings in highly convergent groups, and rather fluctuating rankings in more divergent groups. Users may tend to discount the value of the ranking system if fluctuations and inconsistencies are regularly observed. The fine granularity of our feedback mechanism, as discussed in Section 3, may mitigate this fluctuation effect in divergent groups.
A final consideration with respect to collaborative repositories involves cross-group sharing. If two groups share common interests, some of their URLs may be of mutual interest. To access those URLs, the categories in each group would have to be compared and cross-indexed in some manner, requiring a mapping between different groups' terminology. This vocabulary-matching problem is an interesting and significant challenge in sharing URLs across group memories. Some of the work on building interontology translation schemes may be relevant to this problem [KIF - Genesereth 91].
A larger question regarding the utility ranking system involves the extent to which users are willing to provide feedback regarding the usefulness of Web pages. Following retrieval, there may be a significantly lengthy assessment period during which the user evaluates the utility of the retrieved URLs. It may turn out that the length of this assessment period is inversely proportional to the likelihood that users will provide feedback; once some information has been recognized as useful, the user may not wish to waste additional time,and may immediately proceed to complete the original task that prompted the information. However, if users find the utility ranking feature useful, and understand the critical nature of their role as assessors, they may be more likely to participate in the feedback process.
One approach to ensuring adequate assessment of utility is to make some utility judgments based on indirect indicators. For example, it may be possible to automatically infer whether retrieved URLs were found useful based on whether those URLs were viewed by the user and for how long, or based on how many times the URL is subsequently revisited, etc. Similar approaches have been tried with limited success in other systems (e.g., [ WebWatcher - Armstrong et al. 95]), but there are inherent difficulties with these indirect measurements. In particular, indirect utility measurements will be less accurate and therefore less helpful than direct user feedback.
One advantage of the hierarchical folder organization is the ease of visualizing the structure of stored information. A visual representation helps users conceptualize the relationships among the different information clusters, and consequently helps users to navigate the information space more rapidly [Lifestreams - Freeman 95, Freeman & Fertig 95; Rus & Allan 95]. WebTagger encourages a view of information space as a lattice structure, rather than a hierarchical structure. A visualization based on this lattice structure might help WebTagger users navigate through the information space to locate URLs pertinent to their query.
Various factors such as location, frequency of access, date of last use, relevance for a task, and individual user preference have been shown to be important dimensions for use in classifying, organizing, and accessing personal information. No single factor is of overriding importance, and it is generally recognized that multiple dimensions must be taken into account for effective information access[Barreau 95]. Therefore, an effective personal information management tool should support and combine various organizational schemes, as well as sophisticated indexing, sorting, and searching capabilities.
Several systems have been developed to augment the basic hierarchical organization of bookmarks, for example by integrating the desktop visual metaphor [HotPage and GrabNet], by allowing users to maintain local catalog collections [Catalog Server], or by adding full-text indexing capability [Warmlist - Klark & Manber 95]. Promising innovative designs have been explored for organizing personal electronic media, for instance by using concepts in a semantic taxonomy [Active Notebook - Torrance 95], temporal metaphors [Lifestreams - Freeman 95, Freeman & Fertig 95], or 3-D spatial metaphors involving rooms, shelves, and books [Knowledge Vision].
Because these systems require users to actively take part in structuring and maintaining information, these approaches might not scale up for large information spaces. Other approaches partially or completely automate the information structuring process. Bookmark Organizer [Maarek & Shaul 96] and HyPursuit [Weiss et al. 96] automatically classify a list of bookmarks into hierarchical clusters using text analysis, as well as link analysis. The resulting hierarchy must be tailored interactively by the user, since results of the clustering algorithms are not always intuitive. Compared to manual personal bookmark organizers and automated clustering systems, our approach is semi-automated: users assign categories to URLs, and WebTagger automatically builds a lattice indexing structure, which is used for effective information access.
Feedback has long been used in the information retrieval community to improve upon retrieval results and to route new information appropriately [Salton 89]. To filter Usenet news, Jennings and Higichi use feedback with an embedded connectionist network to model long-term user interests [Jennings & Higichi 93]. Fischer and Stevens apply a rule-based technique to suggest Boolean search agents for Usenet filtering [Fischer & Stevens 91]. [Sheth & Maes 93] employ relevance feedback and a genetic algorithm to support a learning agent for personalized information filtering. More recently, many Web-based systems utilize users' feedback to suggest new Web pages of interest, by means of modeling and learning users' interests over time. Syskill and Webert find a user profile by analyzing the information on a Web page of interest to the user [Pazzani et al. 96]. Fab incorporates adaptive information retrieval techniques to an evolving population of heterogeneous agents searching for Web pages of interest to users [Balabanovik & Shoham 95].
In these approaches, feedback information is often used in formulating a profile of user interests, typically as a collection of indices or subjects. This profile is then used to retrieve additional information of potential interest. In our system, feedback information serves less of a role in gathering new information; instead, feedback is used to improve the organization of information and thereby provide effective access to the most useful URLs.
Several different systems include functionality that enables users to share personal collections of bookmarks. In WebTagger, the problem of sharing bookmarks is tackled by combining inputs from multiple users into a group memory that is accessible via a shared indexing structure. Warmlist [Klark & Manber 95] is a simple extension to basic bookmarking functionality that allows users to access each others' bookmarks stored on a shared filesystem. Active Notebook [Torrance 95] is a system that enables users to share semantic taxonomy structures used in organizing their documents. The Group Asynchronous Browsing Server [Wittenburg et al. 95] builds a database that collects and merges bookmarks in multitree structure to facilitate subject-oriented navigation.
Collaborative filtering methods provide a means of selective information sharing by utilizing preferences indicated by other users. These preferences might be inferred implicitly from the actions of others [Goldberg et al. 92], or might be based on explicit user evaluation. For example, SiteSeer and Grassroots [Kamiya et al. 96] recommend information that has received positive feedback from other users overall, whereas Group Lens [Bergstrom & Riedl 94] and Fab [Balabanovik & Shoham 95] suggest information recommended by a specific subset of users sharing similar interest profiles.
This paper introduced the WebTagger system, a bookmarking service that enables individuals and groups to store, access, and rate the utility of Web-based information with respect to their information needs. In comparison with manual information-sharing methods such as email, this service greatly simplifies the process of sharing URLs within groups. The system's underlying bookmark organization scheme is more natural and flexible than current hierarchical schemes supported by the major Web browsers, and facilitates more rapid access to stored bookmarks. Our bookmarking scheme allows users to concentrate on tagging URLs with the most appropriate categories to facilitate subsequent retrieval, rather than forcing users to select a single best folder within a rigid hierarchical structure. The system also adapts its retrieval rankings in response to user judgements of utility, thereby ensuring that the most up-to-date, useful information is prominently highlighted.
We believe the WebTagger prototype provides a solid foundation for further research into personal information organization. Toward this end, we plan to improve the design of the system by combining some of WebTagger's innovative adaptive and collaborative capabilities with other functionality, including automatic categorization of URLs, explicit user notification of memory updates, and information navigation and visualization facilities.
We wish to thank Dmitry Gerenrot for his implementation of the bookmark importing scheme described in Section 2.4, and for various enhancements to WebTagger's proxy.
Armstrong, R. Freitag, D., Joachims, T., and Mitchell, T. "WebWatcher: A learning apprentice for the World Wide Web", Workshop on Information Gathering for Heterogeneous Distributed Environments, AAAI Spring Symposium Series, Stanford, CA, March 1995.
Balabanovik, M. and Shoham, Y. "Learning information retrieval agents: experiments with automated Web browsing." Workshop on Information Gathering for Heterogeneous Distributed Environments, AAAI Spring Symposium Series, Stanford, CA, March 1995.
Barreau, D. K., "Context as a Factor in Personal Information Management Systems". Journal of the American Society for Information Science 46(5), 327-339, 1995.
Bergstrom, P., & Riedl, J., "Group Lens: a Collaborative Filtering System for Usenet News". MSc thesis., 1994.
Fischer, G., and Stevens, C., "Information Access in Complex, Poorly Structured Information Spaces". Proc. Eighth ACM Conference on Human Factors in Computing Systems (CHI'91), New Orleans, Louisiana, 63-70, 1991.
Freeman, E. "Lifestreams for the Newton" , PDA Developer, Volume 3.4, July/Aug 1995.
Freeman, E. and Fertig, S. "Lifestreams: Organizing your Electronic Life" , AAAI Fall Symposium: AI Applications in Knowledge Navigation and Retrieval, Cambridge, MA, November, 1995. (PostScript) Also published by the Northwest Artificial Intelligence Forum in HTML form.
Genesereth, M.R., "Knowledge Interchange Format", Principles of Knowledge Representation and Reasoning: Proceedings of the Second International Conference, Cambridge, MA, pp. 599-600. Morgan Kaufmann, 1991.
Goldberg, D., Nichols, D., Oki, B.M., and Terry, D., "Using Collaborative Filtering to Weave an Information Tapestry". Communications of the ACM 35(12), 61-70, 1992.
Jennings, A., and Higichi, H., "Personal News Service Based on a User Model Neural Network". IEICE Transactions on Information Systems 75(2), 198-209, 1993.
Kamiya, K., Rvscheisen, M., and Winograd, T., "Grassroots: A System Providing A Uniform Framework for Communicating, Structuring, Sharing Information, and Organizing People", Fifth International World Wide Web Conference Paris, France, May 6-10, 1996.
Klark, P., and Manber, U., "Developing a Personal Internet Assistant". Proc. World Conference on Educational Multimedia and Hypermedia (ED-MEDIA'95), Graz, Austria, 372-377, 1995.
Lewis, D.D. and Hayes, P.J. (eds), Special Issue on Text Categorization, ACM Transactions on Information Systems, 12:3, July, 1994.
Maarek, Y.S., and Shaul, I.Z.B., "Automatically Organizing Bookmarks per Contents", Fifth International World Wide Web Conference Paris, France, May 6-10, 1996.
Mathe, N. and Chen, J.R., "User-Centered Indexing for Adaptive Information Access", User Modeling and User-Adapted Interaction 6: 225-261, 1996.
Pazzani, Michael, Muramatsu, Jack & Billsus, Daniel, "Syskill & Webert: Identifying interesting web sites", Workshop on Machine Learning in Information Access, AAAI Spring Symposium Series, Stanford, CA, March 1996.
Rabinowitz, J., Mathe, N., and Chen, J.R.,"Adaptive HyperMan: A Customizable Hypertext System for Reference Manuals", Proc. Workshop on AI Applications in Knowledge Navigation and Retrieval, AAAI Fall Symposium Series, Cambridge, MA, November, 1995.
Rus, D., and Allan, J., "Does Navigation Require More than One Compass?", Proc. Workshop on AI Applications in Knowledge Navigation and Retrieval, AAAI Fall Symposium Series, Cambridge, MA, November, 1995.
Salton, G., Automatic Text Processing: the Transformation, Analysis, and Retrieval of Information by Computers, Addison Wesley, Reading, MA, 1989.
Sheth, B., and Maes, P., "Evolving Agents for Personalized Information Filtering". Proc. Ninth IEEE Conference on Artificial Intelligence for Applications, 345-352, 1993.
Torrance, M., "Active Notebook: A Personal and Group Productivity Tool for Managing Information". Proc. AAAI Fall Symposium on Artificial Intelligence Applications in Knowledge Navigation and Retrieval, Cambridge, Massachusetts, 131-135, 1995.
Weiss, R., Velez, B., Sheldon, M.A., Nemprempre, C., Szilagyi, P., Duda, A., and Gifford, D.K., "HyPursuit: A Hierarchical Network Search Engine that Exploits Content-Link Hypertext Clustering", Proceedings of the Seventh ACM Conference on Hypertext, Washington, DC, March 1996.
Wittenburg, K., Das, D., Hill, W., and Stead, L., "Group Asynchronous Browsing on the World Wide Web", Fourth International World Wide Web Conference, Boston, MA, December 11-14, 1996.
Richard M. Keller: http://ic-www.arc.nasa.gov/people/keller.html
Shawn R. Wolfe: http://ic-www.arc.nasa.gov/ic/projects/aim/shawn/shawn.html
James R. Chen: http://ic-www.arc.nasa.gov/ic/projects/aim/jchen/jchen.html
Joshua L. Rabinowitz: http://ic-www.arc.nasa.gov/ic/projects/aim/josh/JoshRab.html
Nathalie Mathe: http://ic-www.arc.nasa.gov/ic/projects/aim/mathe/mathe.html
NASA Ames Research Center: http://www.arc.nasa.gov/
NASA Ames Computational Sciences Division: http://ic-www.arc.nasa.gov/ic/
Advanced Interactive Media Group within Computational Sciences Division: http://ic-www.arc.nasa.gov/ic/projects/aim/
Recom Technologies,
Inc.: http://www.recom-technologies.com/
Active
Notebook: http://www.ai.mit.edu/people/torrance/papers/aaai-fall-95.ps
Bookmark
Organizer: http://www5conf.inria.fr/fich_html/papers/P37/Overview.html
Catalog
Server: http://www.netscape.com/comprod/at_work/white_paper/intranet/vision.html#catalog
Fab: http://fab.stanford.edu
GrabNet: http://www.ffg.com/grabnet/
Grassroots:
http://www5conf.inria.fr/fich_html/papers/P24/Overview.html
HotPage:
http://documagix.com/products/dhotpage.htm
HyPursuit:
http://www.psrg.lcs.mit.edu:80/Projects/CRS/HyPursuit/
Knowledge Vision: http://www.towerhill.com
Lifestreams:
http://www.cs.yale.edu/homes/freeman/lifestreams.html
SiteSeer: http://www.imana.com/WebObjects/Siteseer/
Syskill and
Webert: http://www.ics.uci.edu/~pazzani/Syskill.html
Warmlist:
http://glimpse.cs.arizona.edu/~paul/warmlist/
WebWatcher: http://www.cs.cmu.edu/afs/cs/project/theo-6/web-agent/www/project-home.html
Return to Top of Page
Return to Technical Papers Index