
Brian A. LaMacchia
AT&T Labs - Research
600 Mountain Avenue
Murray Hill, New Jersey 07974, USA
bal@research.att.com
We describe in this paper the Internet Fish Construction Kit, a tool for building persistent, personal, dynamic information gatherers ("Internet Fish") [L] for the World Wide Web. Internet Fish (IFISH) differ from current resource discovery tools in that they are introspective, incorporating deep structural knowledge of the organization and services of the Web, and are also capable of on-the-fly reconfiguration, modification and expansion. Introspection lets IFISH examine their own information-gathering processes and identify successful resource discovery techniques while they operate; IFISH automatically remember not only what information has been uncovered but also how that information was derived. Dynamic reconfiguration and expansion permits IFISH to be modified to take advantage of new information sources or analysis techniques, or to model changes in the user's interests, as they wander the Web. Together, these properties define a much more powerful class of resource discovery tools than previously available. The IFISH Construction Kit makes it possible to rapidly and easily build IFISH-class tools. The Kit includes a general architecture for individual IFISH, a language for specifying IFISH information objects, and an operating environment for running individual IFISH.
The majority of Internet resource discovery tools to date have been based on the idea of providing breadth of coverage of World-Wide Web-accessible content. As the amount of content of Web has grown, users are increasingly swamped by the number of matches generated by a query. The popular Web search engines (e.g. Alta Vista) will gladly report, for example, that there are about 30,000 pages containing the phrase "mutual funds"---but asking users to examine even 300 of those documents is unacceptable. Because they attempt to provide comprehensive coverage of the Web to many users simultaneously, these search engines cannot spend much time processing any particular query. Furthermore, they do not take advantage of any user-specific state that may develop as the result of a series of related queries. In contrast, there is a class of resource discovery tools at the other end of the spectrum. These tools interact with only one user and accumulate information about that user's interests over time. They can also spend extended periods of time researching a particular query and return a small set of documents highly-correlated to the user's interests.
There is another problem with the large popular search engines: while these broad-based indexes often provide useful starting points for further resource discovery, they themselves are not sufficient tools for dealing with the growing collection of resources available from Web servers. The problem these search tools have is that they are geared toward indexing static Web content held on static Web servers, and the percentage of Web content that is dynamically-generated is growing. For example, a server that maps ZIP+4 codes to Census population data appears in indexes not as an active service, mapping information of one data type to another, but simply as a static HTML form interface for human users. The index cannot describe the server's contents abstractly or even "look past" the interface to the underlying data. We therefore need to create resource discovery tools that are at least aware of the dynamic nature of the information and content servers around them. Ultimately, we want to be able to describe the contents of Web services in some meaningful way and develop resource discovery tools that can reason about the function and content of servers and about the data discovered in the course of wandering through the Web.
As an example, consider a resource discovery tool that attempts to find a person's physical address and phone number given a name. There are multiple phone book-like services on the Web that can do name-to-number lookups (e.g. Switchboard and Four11) with varying degrees of accuracy, and it is not difficult to create a program that can automatically query each of these services and combine the results in some manner [SE]. However, every time a new, similar service appear on the Web, the new service must be integrated into the existing search tool, and the new service's relationship with every pre-existing service must be explicitly specified. Ideally, we would be required only to describe the capabilities of the new service to the resource discovery tool and the tool would be able to use that description to both access the new service and also relate information from the new service to retrieved information from other indexes. When whitepages.com, a new telephone directory service, shows up on the Web, we want to be able to write a short, concise description of how to access the whitepages.com service, what inputs it expects as part of a query, and what outputs it will yield, and let our search tools figure out automatically how to make best use of that new capability.
The ability to automatically deduce relationship among information retrieved from similar but distinct sources is extremely important in a Web resource discovery tool. Already we have witnessed the creation of an entire class of search services whose job is simply to query other search services in parallel and mix the results together [D,SE]. If the number of primary sources (Alta Vista, etc.) is small then it is possible to code inter-relationships within the primary sources into a meta-index. As the number of primary sources increases, however, the potential number of relationships among those sources increases quadratically, and it becomes increasingly difficult for human authors to keep track of the numerous relationships. Thus, if we can create resource discovery tools that can automatically figure out when a particular Web service may contain relevant information and how that new information relates to previously-known information (that is, if we can remove the human element from that portion of the problem), our tools will be able to discover new, useful relationships quickly even if we ourselves cannot.
In [L] we introduced a new class of resource discovery tools, "Internet Fish," that exist "at the other end of the spectrum." Unlike their monolithic1 server counterparts, Internet Fish2 (IFISH) are semi-autonomous, persistent, personal, dynamic information brokers. IFISH are designed to adapt to changes both in their environment as well as in their user's interests. They incorporate deep structural knowledge of the organization and services of the Web, and are also capable of on-the-fly reconfiguration, modification and expansion. Human users may dynamically change an IFISH in response to changes in the environment, or an IFISH may initiate such changes itself. An IFISH maintains internal state, including models of its own structure, behavior, information environment and its user; these models permit an IFISH to perform meta-level reasoning about its own structure.
This paper describes the Internet Fish Construction Kit for building individual Internet Fish applications. The IFISH Construction Kit includes a general architecture for individual IFISH, a language for specifying IFISH information objects, and an operating environment for running individual IFISH. It facilitates both creation of new IFISH as well as additions of new capabilities to existing ones. We focus here on how the language and architecture help IFISH dynamically incorporate new information sources and types of information into its own structure, as well as recognize when the same information has been discovered from multiple distinct sources; a detailed discussion of IFISH support for long-term user conversations and relevancy-feedback techniques is beyond the scope of this paper. (Readers interested in those topics are directed to [L] for details.) We begin below with some comments on the motivation and design of the IFISH architecture and then proceed to detail the IFISH language and operating environment provided by the Construction Kit.
IFISH live in the World-Wide Web, which is "dynamic" in multiple ways. Therefore, for IFISH to be able to thrive and flourish in the Web, they must be able to adapt and take advantage (where possible) of its changing environment. The Web is dynamic in five broad ways:
A successful IFISH architecture, therefore, must be able to cope with changes in each of these directions. In particular, IFISH must be on-the-fly extensible and customizable. Further, since the types of information that are available change over time, new information sources will introduce new relationships with known sources (relating ZIP codes to population data, for example, when a Census data server is added to the Web). Thus, the IFISH architecture must also allow individual IFISH to discover new relationships automatically and to incorporate those new methods into its structure.
We satisfy these architectural constraints through the use of a data-driven, capability-based architecture for IFISH. By "data-driven," we mean that the operation of a particular IFISH is determined by the information currently known to it. Operations are triggered by the appearance of new information or the discovery of new relationships among previously-known information. The particular operations that are available to an IFISH are specified as declared capabilities, or rules, for transforming information. Thus, in the IFISH universe there are two types of objects: infochunks and rules. An infochunk is a "chunk of information," a piece of information which may be acted upon. Infochunks drive the operation of IFISH; finding new information causes new infochunks to be generated and declared, and those new infochunks in turn cause new processes to occur. Rules are procedures that operate on infochunks and may create new infochunks, modify existing infochunks, or perform some other task (such as creating, modifying or removing rules), possibly with side effects.
IFISH infochunks are containers for pieces of information. They can contain anything: a name, a telephone number, or even a response from an HTTP server (headers and content). Infochunks also contain information about the information they store (meta-information) including how the information was derived and how interesting the information appears to be to the user at the present time. The meta-information stored in infochunks is what allows IFISH to perform self-inspection and examine what IFISH procedures generated useful, interesting results.
Here is an example infochunk, generated by a search request to the mythical whitepages.com telephone directory service. The server was asked for names associated with the telephone number "(617) 868-8042," and returned one entry:
(data "John Doe, 2353 Massachusetts A, Cambridge, MA 02140-1252")
(typeinfo ((known whitepages-response-string) (known string))
(interestingness #[interestingness-structure])
(backward-links
(#[link #[infochunk "(617) 868-8042"]
whitepages/phone-number->whitepages-response-string]))
(forward-links
(#[link #[infochunk "John Doe"]
whitepages/whitepages-response-string->name]))
(invocation-list
((whitepages/whitepages-response-string->name . 816672957)))
Most of the infochunk value slots are self-explanatory. The data slot is a pointer to a raw piece of information, in this case the actual response from the whitepages.com server. The interestingness slot contain an "interestingness" structure for this piece of information; interestingness is an application-dependent scoring mechanism used to provide hints to the IFISH about the order in which information should be investigated. (See [L] for details on interestingness.) The invocation-list is simply a list of rules that have been applied to this infochunk along with a time-stamp of when that rule application occurred; here it records the fact that the "whitepages/whitepages-response-string->name" rule was applied to this infochunk at a particular point in time. The typeinfo slot contains a list of declarations of meta-information concerning the contents of the data slot. Recall that under our assumptions, IFISH cannot assume much concerning the types of information they will encounter out on the Internet. Nevertheless, there is meta-information that IFISH can use to discuss possible types of retrieved information and restrict rule applications to only relevant or well-formed inputs.
Forward-links and backward-links are lists of structures used to weave together individual infochunks into a dependency graph. As the IFISH discovers new infochunks, it remembers not only the new information but also how that information was discovered; that is, what other information led to the discovery of the new infochunk and what information was discovered as a result of this particular information. Links are bi-directional structures that record the destination infochunk, the rule that generated one infochunk from the other, and a time-stamp of when the rule application occurred. We include the rule name here because it is possible to have multiple links, representing different rule applications, between two particular infochunks and we do not wish to elide that information. Similarly, since rule application is not guaranteed static in time, and indeed since rules themselves may change over time, we must allow for the possibility that multiple applications of the named rule will occur and thus the existence and validity of the link may be asserted multiple times. A forward-link from infochunk I1 to infochunk I2 via rule R means that the rule application R(I1) generated infochunk I2; a backward link from I1 to I2 implies that R(I2) generated I1. In our example there is a backward-link from the infochunk containing the response to the infochunk containing the phone number "(617) 868-8042" because the phone number was source information that generated the whitepages.com response. Similarly, there is a forward-link from the infochunk containing the response to an infochunk containing "John Doe" because that name (as the person associated with the given phone number) can be derived from the whitepages.com response.
Infochunks are unique across the contents of their data slots. Discovery of the same data from multiple sources will lead initially to the creation of multiple infochunks, but the IFISH system automatically combines infochunks with equal data slot contents as soon as the duplicate infochunks are added to the running system. As detailed below, this allows IFISH data analysis routines to recognize complementary sources of information.
The second class of objects in the IFISH universe consists of rules. Rules describe procedures that operate on infochunks and perform some task, usually the generation of new infochunks. It is via predefined rules that we build heuristic knowledge into IFISH. Methods for obtaining new information over the network, procedures to identify and parse particular representations of data objects, and even meta-rules that generate new rules that extend IFISH in a particular fashion are examples of the types of heuristic knowledge that can be encapsulated in rule objects.
Every rule in the current implementation of IFISH operates on exactly one infochunk. Each rule in the current IFISH implementation consists of four parts: a name, a precondition, a transducer, and an error-handler. IFISH rules are conventionally named by the typeinfo components of the input and output infochunks (e.g. WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING is the rule the takes a phone number and queries whitepages.com).
A rule's precondition and transducer define respectively what infochunks are acceptable inputs for the rule and what action the rule has with respect to that infochunk. An IFISH working with a particular infochunk determines what rules apply to that infochunk by invoking in sequence each known rule's precondition on the infochunk. Rule preconditions are always Boolean procedures of exactly one argument (an infochunk). The precondition for WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING, for example, checks that the input phone number is of the form "(XXX) XXX-XXXX".
Infochunks that return a value of true when given as inputs to a rule's precondition are in the domain of the rule's transducer. The transducer is the portion of the rule that actually performs work. Usually a transducer applies some operation to the input infochunk, and if new information is generated the transducer constructs a new infochunk to contain that new information, links the new infochunk into the existing hypertext, and "announces" the existence of the new infochunk to the IFISH system. Should an error occur while the rule is running, the rule's error-handler is invoked to handle the signaled condition. Continuing our example, the transducer for WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING queries the server (passing as input the phone number stored in the input infochunk), extracts the useful output (if any) from the resulting HTML page, packages it within a new infochunk, and links the new infochunk to the input infochunk.
Having defined both infochunks and rules, we must now describe how they interact with each other. The basic operation is a rule application, in which a single infochunk is given as input to a single rule. Figure 1 shows the operation of a typical rule application. When applying a rule to an infochunk, the first step is to check that the infochunk is within the domain of the rule (i.e. the rule is applicable to the infochunk). If the rule's precondition evaluates to true for the given infochunk then rule application may proceed. The infochunk is then passed as input to the rule's transducer; the transducer then takes some action and possibly discovers new information. The new information is packed up into new infochunks, and those new infochunks are then linked to the infochunk that was their source: the input infochunk to the rule.
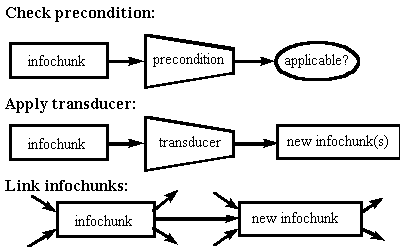
A running IFISH with many infochunks and rules has many possible infochunk-rule interactions; determining which rules should be applied to which infochunk, and the order in which those rule applications should occur, is the function of the IFISH interaction loop. At its most basic level, the interaction loop operates as outlined in Figure 2 below. Each cycle through the interaction loop begins with a check for available resources (a garbage-collection check), user requests to halt execution, or time-dependent events that must be processed. Assuming those checks all fail (which is usually the case), the next step in the loop is to identify an infochunk upon which to work during the cycle. Infochunks are sorted by their current interestingness and the "most interesting" infochunk is identified. This infochunk then becomes the focus of attention for the IFISH until the cycle is completed.
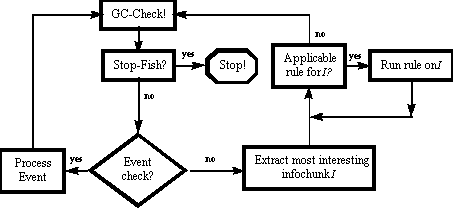
Once the current "most interesting infochunk" has been identified the set of known rules is filtered for those applicable to the infochunk (i.e. rules with preconditions satisfied by the most-interesting infochunk). Each applicable rule is then run in turn on the infochunk under study until every applicable rule has been processed; when finished, the interaction loop then starts over. (Every IFISH rule application occurs within a protected environment so that errors may be caught and handled when they occur.)
Notice that the interaction loop does not itself impose any sequential execution constraints on the IFISH. Execution order is determined strictly by the relative interestingness of the infochunks currently available. Thus, in a multiprocessor environment an IFISH may spawn multiple tasks simultaneously so long as shared areas of memory are guarded against overlapping accesses. (The current IFISH implementation in fact uses multiple execution threads to allow simultaneous execution of the interaction loop itself as well as the miniature WWW server that is used to provide user interaction.)
Given the desired IFISH architecture described above, we now proceed to define a language that can be used to write the infochunks and rules that together describe an IFISH. Recall that IFISH are data-driven, capability-based creations. Their behavior is defined by what information is known to them and what rules (capabilities) they have for manipulating that information to generate new information. Execution of tasks (rule applications) in the IFISH is nominally controlled by the IFISH interaction loop, but as pointed out above, the interaction loop schedules IFISH tasks based on intrinsic properties of the infochunks themselves. Thus, in order to create a new IFISH it is necessary to define the rules and information that are known to the IFISH initially, but not how those rules should be cascaded together. We are thus led naturally to create an IFISH language that is declarative in nature, not imperative. Users define IFISH by declaring the existence of particular pieces of information and capabilities for transforming information.
The IFISH language (and, indeed, the entire IFISH system) is implemented on top of MIT Scheme [RC], a dialect of LISP. IFISH language constructs are implemented as Scheme procedures or syntax macros that modify global state within the IFISH execution environment. The primitive components of an IFISH, its infochunks, transducers and rules, may thus be written as expressions within this extended version of Scheme.
New information is added to an IFISH by first creating a new infochunk structure to contain the information and then making the IFISH aware of the new infochunk. Infochunks are just Scheme data structures; they are usually created by transducers when new information is discovered but may be created manually to provide bootstrap information to an IFISH. For instance, here is the expression for creating the bootstrap infochunk in the whitepages.com example (semicolons ";" are comment characters in Scheme):
(define whitepages-seed-infochunk (make-infochunk "(617) 868-8042" ; data '((known phone-number) (known string)) ; typeinfo )
The arguments to make-infochunk are respectively the data and typeinfo components of the infochunk. Here the data being stored is a string containing the phone number. The associated typeinfo for the URL is a list of two declarations: (known phone-number) and (known string). (In the whitepages.com example "(known phone-number)" identifies the string as representing a phone number in canonical form.) The other four infochunk slots: interestingness, backward-links, forward-links and invocation-list, are determined by the IFISH system itself and need not be specified by the infochunk creator. (Interestingness is computed separately via another function, links are created as new infochunks are connected to infochunks already in the system, and the invocation-list is automatically maintained as a by-product of the IFISH interaction loop.) Once an infochunk has been created the IFISH must be notified of its existence:
Announce-new-infochunk places the infochunk within the purview of the IFISH system and adds it to the collection of infochunks waiting to be processed by the interaction loop.
Announcing a new infochunk to the system has an important side-effect: if the data inside the infochunk being announced is already known to the IFISH through another infochunk, the two infochunks (old and new) are merged into one combination infochunk. The combined infochunk has the same data as before, but the forward-link (respectively backward-links/typeinfo/invocation-list) slot of the combined infochunk is the union of the two forward-links (backward-links/typeinfo/invocation-list) of the two source infochunks. In particular, data that has been discovered from multiple sources will generate a combined infochunk with multiple backward links (one link to each of the generating infochunks). The link structure thus captures some of the meta-structure of the discovered data, and analysis routines (or interestingness rules) can take advantage of this information. For example, if both whitepages.com and switchboard.com found "John Doe" associated with the phone number "(617) 868-8042," the infochunk containing the name would contain multiple backward links, one for each service:
(data "John Doe")
(typeinfo ((known name) (known string))
(interestingness #[interestingness-structure])
(backward-links
(#[link #[infochunk "(617) 868-8042"]
whitepages/whitepages-response-string->name])
(#[link #[infochunk "(617) 868-8042"]
switchboard/switchboard-response-string->name]))
(forward-links ())
(invocation-list ())
IFISH rules are declared present and available to the system just as infochunks are. Recall that every IFISH rule consists of a symbolic name, a precondition, a transducer and an error handler:
(DEFINE-RULE 'WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING (SIMPLE-TYPE-PRECONDITION '(known phone-number)) transducer/whitepages/phone-number->whitepages-response-string default-error-handler)
Rules are declared via the DEFINE-RULE macro; DEFINE-RULE builds a new rule out of the specified component parts and installs that rule into the system so that it will be available to the IFISH interaction loop. This example shows the rule declaration for the WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING rule, which queries whitepages.com about particular phone numbers. The precondition for this rule (the SIMPLE-TYPE-PRECONDITION3 clause) is only satisfied by infochunks that have a typeinfo declaration (known phone-number). Preconditions may be arbitrarily complex, as they are simply Scheme functions. The actual work of generating new information (querying the whitepages.com server and constructing new infochunks) is performed by the transducer transducer/whitepages/phone-number->whitepages-response-string.
The meat of an IFISH rule is its transducer; it is the transducer that creates or discovers new information, or creates links between two pieces of previously-unrelated information. Like rule preconditions, transducers may be arbitrarily complex Scheme procedures of a single infochunk argument. Most transducers perform three basic functions in sequence:
If a transducer is performing multiple analyze-discover-announce operations, then it is likely combining multiple simple data transformations into a single, complex operation, which is not generally desirable. Transducers should be kept simple; combinations of transducers are best deduced by the IFISH system, not anticipated by the author(s) of the IFISH.
To continue our example, here is the transducer portion of the rule WHITEPAGES/PHONE-NUMBER->WHITEPAGES-RESPONSE-STRING ("lambda" is the procedure introducer in Scheme):
(DEFINE-TRANSDUCER
transducer/whitepages/whitepages-response-string->name
(lambda (infochunk)
(let* ((phone-number (infochunk/data infochunk))
(the-raw-result (whitepages/make-request phone-number))
(parsed-result (whitepages/parse-result the-raw-result)))
(if (not (null? parsed-result))
(let ((new-infochunk
(make-infochunk parsed-result
'((known whitepages-response-string)
(known string)))))
(ANNOUNCE-AND-LINK new-infochunk))))))
The transducer begins by taking apart the contents of the data slot of the input infochunk to extract the phone number. Notice that the transducer does not perform any error checking or structure tests before it tries to extract information; those applicability tests were performed as part of the evaluation of the rule's precondition. The transducer then proceeds to make the raw HTTP request (we assume that functionality is performed by the helper application whitepages/make-request) and parse the result. If there is a legitimate response, a new infochunk is created to contain the response and this new infochunk is installed via the ANNOUNCE-AND-LINK macro. ANNOUNCE-AND-LINK announces the new infochunk to the system, computes the infochunk's interestingness, and then links the input and new infochunks together with links that reference each other, the rule that created the link and the time the link was created.
Now that we have described how a single rule is constructed and added to an IFISH we may look at how complex information transformations may be similarly encoded. At first glance, authors may be tempted to create very complex transducers that combine many intermediate information transformations into one rule application. However, by manually combining multiple primitive operations into a single, monolithic procedure object we will deprive the IFISH system (in particular the interaction loop) of the possibility of discovering new combinations of those primitive operations. Since IFISH operation is data-directed we need to create transducers and rules that do not hinder that direction.
As an example, consider the processing an IFISH must accomplish to de-reference a URL, presented as a string, and obtain the URLs of all of its anchors (hyperlink references). (URL handling and primitive HTTP operations are included in the base IFISH system.) At a minimum, the following tasks must be performed:
The default IFISH system includes a rule for performing each step of this process:
By breaking the task up into primitives that convert one data type into another (e.g. URLs to HTTP headers) we can later easily integrate other data transformations into the IFISH without having to explicitly "connect" the new rules to the existing rules. For example, one of the possible HTTP errors that can result from a HEAD request is a redirect notice that the contents of the requested URL may be found at another URL (HTTP error code 302). Extending IFISH to handle redirect notices was easy, because all that was needed was a single rule that recognized certain types of HTTP-REQUEST-HEAD structures and extracted the new URLs from "Location:" headers returned by the HEAD request.
The power of data-directed programming for IFISH is even more evident when we look at IFISH interfaces to a collection of related Web database servers, such as the phone book servers (Switchboard, Four11 and our example whitepages.com). Abstractly all have roughly the same interface: users give each server a name, address or phone number to search on and the services return lists of corresponding entries. The syntax of the requests and responses may be different in each case but the data types of the requests and responses are the same. Thus, we can define service-specific transformations that accept names and return phone numbers for each service, and any time IFISH deduces a new name the appearance of that name will trigger requests to each of the on-line databases. Further, whenever a new " whitepages-like" service appears on the Web all that needs to be done to incorporate in into the IFISH is to write service-specific rules for the new engine. As soon as the new capabilities are declared previously discovered names and phone number will trigger searches on the new service.
Talking to information sources on the Web comprises only part of an IFISH's function; IFISH also communicate with users, and therefore the IFISH architecture and language must also support user interaction. We have already shown how IFISH can communicate with Web servers; assume now that we wish to interact with a particularly ill-behaved service, one which has the following properties:
Any service on the network sharing these properties might be rationally classified as "misbehaved." Consider for a moment, though, how user queries must appear to an IFISH, and it becomes apparent that user interaction from the IFISH perspective is dealing with a remote service that misbehaves. The fact that interactions with the user may be viewed as just another network communication by an IFISH suggests that we not attempt to create a sui generis system for user-interaction but rather that we try to incorporate it into the IFISH substrate that already exists. Questions to users are generated by IFISH rules just as other infochunks are; user questions are simply a special type of data structure stored in an infochunk's data slot.
The Internet Fish Construction Kit provides a general framework for building resource discovery tools. To date, two independent applications have been built using the IFISH Construction Kit, and there are more projects currently under development. The first IFISH to be "declared" (written) and used was the Finder IFISH ([L]). The Finder IFISH is tailored to finding Web pages that relate to a set of Web pages specified by the user. "Relatedness" is measured in part using a document vector clustering model ([E]) and in part using heuristics based on hypertext link geometry. Users bootstrap the Finder IFISH by providing (via infochunk declarations) an initial set of Web page URLs or keywords that are relevant to the user's interests. The Finder IFISH then proceeds to use that information to generate new information (including Web pages and keywords) using its own analysis procedures and publicly-accessible search engines.
The second IFISH application built on top of the construction kit is a "home page finder" written by Ellen Spertus [S]. Ellen's IFISH is launched given only the name of a person; its goal is to find one or more Web pages that it thinks are likely home pages for the given person; candidate pages are presented to the user in order of perceived likelihood (i.e. higher interestingness score). The IFISH primarily looks for HTML anchors with the name of the target person (or a shorter version) as text contained within the anchor. The target of the anchor then becomes a candidate page. Perceived likelihood of the candidate page being a desired home page is modified based on characteristics of the page contents, URL, and server directory structure. Additional IFISH projects currently underway include a port to Java (so that individual IFISH can run directly inside a user's browser, instead of requiring a second, stand-alone server) and a networking application that uses the IFISH reasoning model in a non-Web environment.
These projects have proven that the Construction Kit permits rapid assembly of IFISH-class resource discovery tools but they have also highlighted some areas of the construction kit that need improvement. The most important deficiency of the IFISH Construction Kit is that it does not currently include a robust relational database for storage of the infochunk structure. The entire linked infochunk structure (except for data slot contents themselves4) must be stored in core memory, and thus the overall number of infochunks that can be created and stored is limited. Ideally, the IFISH system should be combined with a persistent object store that would provide easy and rapid access to any portion of the linked infochunk structure.
We have described in this paper the IFISH Construction Kit, a tool for building persistent, personal, dynamic information gatherers ("Internet Fish") for the World-Wide Web. The IFISH Construction Kit consists of three components: an architecture for designing individual IFISH, a declarative language for writing IFISH, and a runtime system for operating individual IFISH written in the language of the Construction Kit. Internet Fish written using the Construction Kit may be dynamically extended or modified to cope with the ever-changing nature of the Web. As new information sources appear, new capabilities can be written and loaded into running IFISH. IFISH are also able to reason about their own effectiveness since they automatically keep track of how information was discovered as well as what information was found. Together, these properties define a much more powerful class of resource discovery tools than previously available. The IFISH Construction Kit makes it possible to rapidly and easily build IFISH-class tools.
The research described here is part of a doctoral dissertation completed under the supervision of Gerald J. Sussman at the Artificial Intelligence Laboratory of the Massachusetts Institute of Technology. Support for the Laboratory's artificial intelligence research is provided in part by the Advanced Research Projects Agency of the Department of Defense under Office of Naval Research contract N00014-92-J-4097.
[D] D. Dreilinger. SavvySearch home page. Available from URL: http://www.cs.colostate.edu/~dreiling/smartform.html
[E] Excite, Inc. Excite for Web Servers (EWS). Available from URL: http://www.excite.com/navigate/home.html. Previously distributed as ``Architext Excite for Web Servers'' by Architext Software. ``Architext Software'' is now Excite, Inc.
[L] Brian A. LaMacchia. Internet Fish, AI Technical Report 1579, MIT Artificial Intelligence Laboratory, Cambridge, MA (1996) Available at URL: http://www-swiss.ai.mit.edu/~bal/thesis/ifish-tr.ps.gz
[RC] J. Rees and W. Clinger, eds. "The Revised4 Report on the Algorithmic Language Scheme." Lisp Pointers 4(3), ACM, 1991.
[S] Ellen Spertus. Mining Links. Thesis proposal, MIT Department of Electrical Engineering and Computer Science, September 1996.
[SE] E. Selberg and O. Etzioni. "Multi-Service Search and Comparison Using the MetaCrawler." In Proceedings of the Fourth International World Wide Web Conference. World Wide Web Consortium, 1995. Available from URL: http://www.cs.washington.edu/research/projects/softbots/papers/metacrawler/www4/html/Overview.html
1"Monolithic" here refers to the logical representation of the server to the user. The fact that a server may be fully replicated across multiple machines for performance reasons doesn't change the basic model.
2We call these tools "Internet Fish" because they "swim" in the "sea of information" that is the Internet looking for "tasty bits of information" to consume and digest.
3SIMPLE-TYPE-PRECONDITION is a macro for common types of preconditions that match against the typeinfo of an input infochunk. The details of its operation are discussed in [L].
4A facility within
the IFISH system allows large data slot contents to be automatically
spilled to disk, and the bodies of HTTP requests are also automatically
stored on disk. Data spillage is transparent to the user and the
rest of the IFISH system. The link structure, however, is currently
stored in memory and thus inherits MIT Scheme's heap size limitations.