
Tim Mills, Ken Moody, and Kerry Rodden
University of Cambridge Computer Laboratory
Pembroke Street, Cambridge CB2 3QG, United Kingdom
Timothy.Mills@cl.cam.ac.uk,
Ken.Moody@cl.cam.ac.uk,
Kerry.Rodden@cl.cam.ac.uk
A unique collection of historical material covering the lives and events of an English village between 1400 and 1750 has been made available via a Web-enabled information retrieval system. Since the expected readership of the documents ranges from schoolchildren to experienced researchers, providing this information in an easily accessible form has offered many challenges, requiring tools to aid searching and browsing. We have replaced the file structure of the document collection by a database, enabling us to present query results on the fly. A Java interface displays each user's context in a form that allows for easy and intuitive relevance feedback.
An important collection of historical records is being mounted on a World Wide Web server, and a search engine based on an architecture for multimedia information retrieval has been constructed to guide researchers in their use of the sources. These records have already been made available on microfiche, and historians from several continents have published studies based on them. By comparing earlier experiences with those of historians who are currently accessing the same data through the Web we hope that the practical benefits of our information retrieval (IR) system will become evident. Once we feel confident that the basic architecture is sound we shall move on to the next phase of the project, which is to set up a second set of documents which include photographs, video and audio components as well as straight text.
Since we regard critical evaluation by end users as central to the success of the IR project an important secondary goal of our work is to facilitate academic research based on the historical records. It is therefore important to create an appealing interface to the collection. The documents are provided to a worldwide readership, and so registration and subsequent logging of users may allow conclusions to be drawn about the effectiveness of the system in terms of retrieval performance and usability.
In 1972 the UK Social Science Research Council initiated a project in which three communities would be examined with the aim of reconstructing as fully as possible the lives of individuals who lived in these selected areas [Mac89]. One of the places chosen was Earls Colne in Essex, England. The rich collection of historical records describing the village between 1400 and 1750 were transcribed, numbered and manually annotated, identifying each instance of an entity from a number of predefined categories [MHJ77]. These annotations included delimitation of dates, names, kinship relations, places and land transfers. Of particular importance to the users of these records are instances of people, places and dates.
The resulting transcriptions and indices derived from them were published in microfiche form. The plain text of the records comprises about thirty megabytes, while manual annotation adds several megabytes more. Although in contemporary information retrieval terms this is not a large amount of data, for those who wish to study the material in detail the collection is of an intimidating size.
The published microfiche has led to a considerable amount of historical research, but the quantity of information and the format make navigation cumbersome. The intention had always been to make the database globally accessible, but the electronic technology of the time was not sufficiently developed to make this possible. Some fifteen years later, the advent of the World Wide Web has at last made this feasible. Further, hypertext systems provide a much more convenient way of navigating, since links support traversal of the documents by following references to individuals, land holdings and chronology.
The data collection will grow as a result of research on the documents. For example, a number of PhD theses are currently in progress, and references to them will be added as they appear. In future work we hope to provide an online environment for group discussions. This means that a Web site is a more appropriate context for presenting the collection than a static database such as a CD-ROM.
To enable users with varying levels of experience to access the sources conveniently, both searching and browsing of the information have been provided via four supporting technologies, namely hypertext, object-oriented database, information retrieval software and client-side scripting.
Although the data could have been indexed by an existing Web search engine, an approach that exploited the existing markup format was chosen so that stronger semantics could be expressed at search time. In addition to normal keyword matching, dates, people and land areas can be specified explicitly. This means, for example, that all references to a woman can be retrieved even if that woman has changed her name after marriage. This facility is considered essential for this collection.
The original form of the data was inconvenient for processing, since it contained duplicate information and the results of nominal record linkage were separated from the main text.
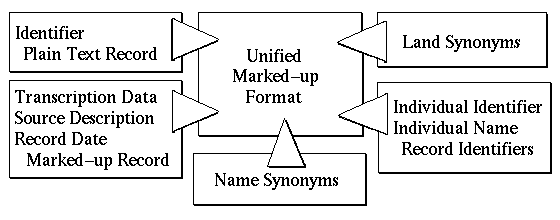
Figure 1.
This figure illustrates the different forms of information to be integrated. This process resulted in a single file for each of the historical sources, from which other formats could easily be generated. This unified format is stored as records in the OODB, and HTML is generated automatically at query time. An example record is given below.
<DOCUMENT>
<IDENTIFIER> 0140.00552 </IDENTIFIER>
<TYPE> PRO STAC8/289/30 in ERO transcript </TYPE>
<DATE date=25.11.1606> 25.11.1606 </DATE>
<TEXT>
<NAME identity=H206 name="Richard Harlakenden"> Rich Harlakenden </NAME> forced to enter a bill for forcible detainment of <NAME identity=F314 name="Wm Ford"> Wm Forde </NAME> and others <NAME identity=F314 name="Wm Ford"> Wm Forde </NAME> found guilty of forcible detainment of <LAND identity=152 name="Chalkney Mill"> Chalkney Mill </LAND> and <NAME identity=H206 name="Richard Harlakenden" > Harlakenden </NAME> was put in possession by the sheriff through a writ of restitution
</TEXT>
</DOCUMENT>
The data itself presents some interesting problems. Firstly, some of the original documents were damaged or partially illegible, so the meaning of some of the words has been lost. A great deal of work has been carried out by experts to determine the set of individuals referred to in the collection. Manual indexing of the references to these individuals has allowed this domain specific information to be encoded in the file format and exploited during hypertext and index generation.
Two distinct individuals may share the same name, and one individual may have more than one name, or a name may have a number of possible spellings. Thus within the text, people's names are marked up with a unique identifier and a normal form of their name. In the above example, "Richard Harlakenden" has identifier H206, which distinguishes him from his five namesakes in the collection.
Since land boundaries change over time, land names are identified by a series of numbers which refer to land regions, each identifier having a lifetime in much the same way as a reference to a person. Here "Chalkney Mill" has identity 152.
Dates are annotated by adding a standard form, since in the original text dates could be given as day-month-year triples, month-year pairs, or single years. As a further complication, dates could refer to festivals such as Christmas, and years could be given as regnal dates, for example, 3Eliz1 refers to the third year of Queen Elizabeth I's reign. Date ranges were also used. All dates were therefore automatically annotated with a normal form of the date.
Initially a hypertext which mirrored the existing microfiche collection was constructed. Each record has a unique identifier, and these identifiers serve to group records from the same source, such as baptism records. By ordering the records by their identifiers and dividing into page-sized units, sequential browsing was provided. Later the equivalent of a table of contents was created for the collection.
Additionally, the markup information is used to generate further hypertext links to aid navigation. Since individuals, lands and dates had been identified, indices of these attributes were generated. For example, an alphabetic index to the individuals allows access to all records containing that individual. Chronological access is supported by hyperlinks between dates appearing in documents and corresponding index pages.
The generated hypertext offers a number of advantages over the microfiche publication. Both media types allow sequential navigation of the document collection, but the hypertext also allows easy movement through the collection by date, by individuals and by lands. Although this was possible with the microfiche format, the process involved finding a name, locating the identifier for that name, and then searching the name index to find record identifiers for the required records. This tedious and time-consuming sequence is replaced by hypertext links. For example, when viewing a record, a reference to an individual forms a link to the index of people, thus allowing all other records referring to that individual to be reached. The hypertext indices also aid users unfamiliar with the material, since it becomes much easier to trace paths of interest via the links. This should prove particularly useful when making the collection available for such purposes as high school history projects.
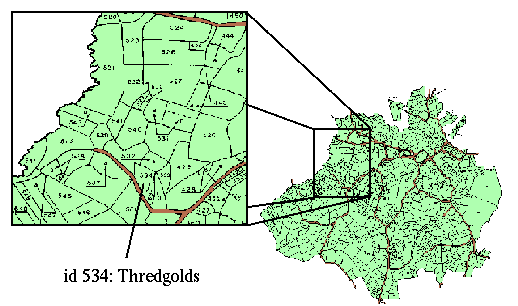
Figure 2.
The site also contains images of selected source documents and photographs of Earls Colne, including pictures of several of the houses in the village which have changed little since the 17th century. Maps illustrating the land plots have been coupled with client-side image maps. This allows navigation of the land index by selecting plots of land on the map.
The text of the documents corresponds exactly to the original, apart from translation from mediæval Latin where needed, and some standardisation of spelling. The data is often hard to interpret, and so introductory information has been included in the site which gives a background to the collection and the period. Notes are provided to guide browsers, stressing particularly the difficulty of identifying individuals from names reliably.
Cobra (COntent-Based Retrieval Architecture) [Mil97] is a framework for developing multimedia IR applications. The system allows construction of IR applications at several levels of complexity. At the simplest level, an application is composed of high level management modules to deal with filesystems, existing document types, user interfaces, query languages and retrieval models.
Cobra is an extension of object-oriented database technology which enables application developers to describe at the schema level the way in which documents should be indexed. The basis of the architecture is a model for multimedia documents which combines different indexing features to build up a composite document representation. Tools such as stemming and filtering may be applied to transform between representations. Documents are described by document classes which declare the representations and tools associated with the document.
Object orientation facilitates quick exchange of component modules, and thus promotes reusability and tailorability. Through object specialisation, the system may be expanded and enhanced to meet the emerging requirements of new media types.
More sophisticated systems will depend on handling a variety of media types and formats. This is catered for by defining new document class objects. These objects define the tools and features that are used to represent the document together with a method for parsing the document. This may simply involve composing existing tools and feature representations, but it may be necessary to create new ones. Of course, once written these tools and representations are available for future use.
The Cobra framework was implemented after studying the possible interactions between system components. Since modularisation aims to produce self-contained units, the points of separation have to be balanced against the functionality desired. For example, components such as the user interface may be extremely complex and require an understanding of the underlying document components, in order to provide facilities such as highlighting of search keywords in the retrieved documents. So a tradeoff between generality and reusability is inevitable. By specialising components, the functionality provided by more general modules can be reused when refining them for a particular application.
The current implementation supports text, audio (from a speech recognition system) and image media types. The facilities for constructing new document classes currently include textual and numerical representations, dates, RGB colour values and file information. These representations may be modified by tools including a morphological stemmer and a stop-word filter, and the resulting sets stored in the database via an inverted file.
As the architecture developed, it became evident that an extra facility was needed to allow for events requiring interaction with or communication to the user. So that the user can form a coherent mental model of an IR system, it is helpful to provide some indication of how a query has resulted in the retrieved documents. An example is the case of stopword filtering, in which the act of removing a common term should be signalled to the user. Callbacks may be registered with tools so that if an event of a particular class occurs, information characterising it may be notified by the tool to the user interface. This mechanism was to prove invaluable in handling the peculiarities of the Earls Colne data.
A number of simple retrieval applications have already been built, including a generic Web site indexer, and a general document store, which has been used for electronic mail messages, bibliography files, manual pages etc.
The search engine was constructed to take account of the various types of information represented in the document collection by composing standard Cobra components to define a new document class. Attributes hold the document title, record catalogue identifer and the document body. Text representations handle free text, individuals and plots of land while a date representation deals with dates. The tools which are applied to these representations include a stemmer and stopword filter for the free text, and a synonym tool for the name and land representations.
As the records are added to the database, the document parser extracts the content-bearing features from the annotated text. The resulting search engine is a probabilistic system based on the inference model [TC91].
Since users would find it unacceptable to refer to individuals by identifiers rather than by name, the user interface is responsible for refining the query so that the assignment of names is made apparent to the user. During the parsing of a query, if the synonym tool finds an ambiguous name, the reporting mechanism is used to terminate the query processing and to present the possible options for the user to select. This is important, since the problem of deciding how to map names to individuals has no self-evident solution. Thus, if a user doubts the assignment of identifiers to individuals made by the (human) indexers, system behaviour can be adjusted during query refinement.
The interface also provides support for relevance feedback, an information retrieval technique which has been shown experimentally to provide significant performance improvements [HC93].The user submits a query, browses the results, and then selects those results which she regards as particularly relevant to her query. This allows the system to refine the query by adding in new terms from the selected documents, and altering the weights of the original terms. This is more helpful than leaving the reformulation entirely to the user, who may already have made her best attempt at a query. Existing Web search engines do not normally take advantage of relevance feedback, since the stateless nature of HTTP makes it difficult to implement: to change the display in any way the page has to be reloaded.
From previous studies (for example [YLYL95]) it is evident that users often do not use relevance feedback facilities when they are available. Two reasons may account for this. Firstly, users who do not require every piece of relevant information may be provided with enough useful results after an initial search. We believe that expert historians and anthropologists searching the Earls Colne collection will want to find every piece of information relevant to their research: discussion with users of similar collections has confirmed this.
Secondly, users may not have an adequate mental model of what relevance feedback is and how it affects their query. Work by Koenemann and Belkin [KB96] has shown that making the relevance feedback process more visible to users and giving them control over the expansion of their queries can greatly increase the system's effectiveness. Our user interface has thus been developed to make the effects of feedback explicit. We overcame the limitations of HTML forms by writing our query interface as a Java applet. This has helped to facilitate a session-based model of interaction, in which state is maintained at the Java client. We can also have more control over adapting responses to suit the user, and keep detailed session logs. These can be used to gauge the effectiveness of the query interface, and to examine user search patterns.
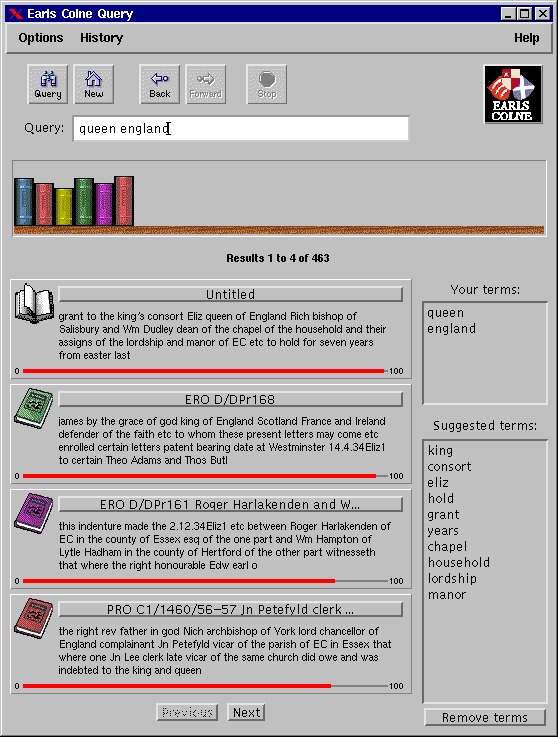
Figure 3.
The query interface is illustrated. The user enters an initial query and is presented with a list of results. She can view a result in her Web browser by clicking on its title; the open book icon shows which of the results is currently being viewed. After looking through the document, she may decide to indicate that it is relevant to her query, which she does by clicking on the result. Whenever a result is marked or unmarked as relevant, the list of suggested extra terms is updated. This is known as incremental query expansion [BDPJ97]. The user has the option to remove those terms she does not wish to have added to her query, and can then submit an expanded query.
To provide the user with a reminder of which documents she has picked out as being relevant, we adopted the metaphor of a bookshelf: for each document selected, a book icon appears on the shelf. The size of the book gives an indication of the length of the document, and the colour can be used to classify it into an application-specific category (in this case, the source in the collection). A document may be deselected by clicking on the book. Moving the mouse over a book shows the title of the document it represents.
The interface currently supports full-text querying, including phrases. Due to the special markup of the Earls Colne data, we can also allow the user to explicitly search for dates, names, or lands. Currently this involves specifying an attribute-value pair in the query, such as "land:Chalkney". We plan to experiment with the provision of separate fields in the interface for querying according to these attributes. There is also an experimental query history facility, enabling the user to re-issue any of the queries from the current session. The ``back'' and ``forward'' buttons allow sequential movement through the history, and a separate menu option affords direct access to any query. Unfortunately, Java's current security restrictions make it impossible to store the history on the client side between sessions.
The first application of the Cobra system has been to provide access to the text of historical records in conjunction with a hypertext, and to allow selection of the records associated with named entities such as individuals and plots of land. Currently the records are being further processed to allow access to kinship relations and to view land transactions.
We hope to augment the database with additional information such as an animated map showing the changing pattern of land tenure through time. Ralph Josselin, a parish priest who lived and farmed in the village, kept an often detailed diary from 1638 until his death in 1683. The text of this diary has been entered into the computer and marked up for inclusion in the Web server. These additions together with the background and photographic material should make the server attractive to a wider class of client, including school history departments.
More investigation is required to determine how the information can best be displayed, together with evaluation of the retrieval interface. We intend to monitor sessions, and to set up a registration system so that we can record the suggestions of those who have used the server. We think that the data will have wide appeal, so that we shall learn from the experience of users with greatly varying levels of sophistication.
Mounting the Earls Colne data on a Web server will be of real service to historians interested in that period, as well as offering useful primary source material for school projects. But our main purpose is to gain understanding of the needs of such users before trying to evaluate the Cobra architecture in more challenging contexts. The work described here is almost complete, and the site will shortly be made available to a small user community before large-scale access is permitted.
The Cobra system is currently being extended to handle more media types, and more representations of the supported media types. The potential of the representation model is being examined by case studies of existing real-world multimedia retrieval problems. Cobra is designed to be a practical retrieval tool, and forthcoming experiments will continue to emphasise real-world problems.
In future work, the system is to be applied to multimedia anthropological sources. This information includes film clips and photographic data, and will pose extra challenges which arise from the need to retrieve documents of media types other than text. We believe that user interaction will play a key role in building a useful IR engine, and we are anxious to develop a robust system structure with text data before carrying out experiments with other media. The two sets of data have been collected by the same social historian, Alan Macfarlane, and the common underlying philosophy should help us to extend experience gained with the text retrieval system into a multimedia context.
If a search query is posed against a collection that contains documents of more than one media type, then the matching function must combine index terms which have different semantics. This general area (data fusion) is an active research topic: experiments with real users are required in order to validate a selected fusion technique. A quite separate and equally difficult problem is to design the user interface for multi-modal queries, in particular for handling relevance feedback.
The real tests of the Cobra architecture will be twofold. First, will it be possible to experiment with the structure of the IR engine in a modular fashion? An example would be to modify the way in which relevance feedback causes query refinement. Secondly, can such experiments be carried out as easily with multimedia as with text documents? The object-oriented structure of Cobra and the flexible nature of the document representation have been designed with such requirements in mind, but there will be many lessons to be learnt from the experiences of real users.
Developing a Web site to present the Earls Colne data has been fun, largely because the documents themselves are inherently interesting. Alan Macfarlane and Sarah Harrison have spent a large part of the past twenty years gathering and organising the data, and we have relied on their advice. We have also learnt from the experiences of a number of historians accessing our prototype, notably Thomas Bacon. Our colleague Jean Bacon has made valuable comments on this paper.
We acknowledge the UK EPSRC for supporting this work both through studentships and under grant GR/J42007. We are grateful to ICL for general support of our research group. Finally, Persimmon IT Inc. are making a significant contribution of both equipment and time that has allowed us to establish the Earls Colne site on the Internet.