
Towards a Multimedia World Wide Web Information Retrieval Engine
Sougata Mukherjea, Kyoji Hirata and Yoshinori Hara
C&C Research Laboratories,
NEC USA Inc.
sougata@ccrl.sj.nec.com,
hirata@ccrl.sj.nec.com,
hara@ccrl.sj.nec.com
Abstract
Search engines are useful because they allow the user to find information
of interest from the World Wide Web. However, most of the popular search
engines today are textual; they do not allow the user to find images from the
Web. This paper describes a search engine that integrates text and image
search. One or more Web sites can be indexed for both textual and image
information, allowing the user to search based on keywords or images or both.
Another problem with the current search engines is that they show the results
as pages of scrolled list; this is not very user-friendly. Therefore our search
engine allows the user to visualize the results in various ways. This paper
explains the indexing and searching techniques of the search engine and
highlights several features of the querying interface to make the retrieval
process more efficient. Examples are used to show the usefulness of the technology.
With the explosive growth of information that is available through the
World Wide Web, it is becoming increasingly difficult for the users to find the
information of interest. Therefore, various searching mechanisms that allow the
user to retrieve documents of interest are becoming very popular and useful.
However, most of the popular search engines today have several limitations:
- The search engines are textual; given one or more keywords they can
retrieve Web documents that have those keywords. Although most Web pages have
images, there is no easy way for the user to specify an image and retrieve Web
documents containing images similar to it.
- The retrieved documents are shown as pages of scrolled lists. If lots of
documents are retrieved, this is not very user-friendly.
- Although the search engines retrieve the documents that match the user-specified keywords, there is no indication about the position of the documents
in the Web site from which they were retrieved.
We have implemented a search engine, Advanced Multimedia Oriented Retrieval
Engine (AMORE), that tries to remove these limitations. First, it
integrates image and text search. Web sites can be indexed for both textual
information and images contained in and referenced from the HTML documents. Like
other search engines, our engine allows the user to search for Web documents
based on keywords. Additionally, the user can also retrieve Web documents
containing images similar to an user-specified image. The image and text search
can be also combined by and or or. The retrieved documents are
displayed to the user sorted by the number of keyword-matched lines in a
scrolled list. The user can also view the retrieved images sorted by their
similarity to the selected images. To enable the users to better understand the
search results, we also provide various types of visualizations of the results.
Moreover, we have developed a new kind of visualization called the
focus+context view of Web nodes which helps the user to understand the
position of the node in the Web site from which it was retrieved.
Our overall objective is to develop a multimedia information retrieval engine
for the World Wide Web. The engine should integrate browsing and querying,
allowing users to find the information they want using querying by
successive refinement. The user should be able to search for documents and
other media objects of interest. If lots of information is retrieved, browsing
through the results using the visualizations will be helpful. On the other
hand, if very little information is retrieved, views like the focus+context
view will allow her to look at other related information. Then the user may
issue a more appropriate query.
Section 2 surveys related work. Section 3
explains the indexing and querying mechanisms. Section 4
presents examples to illustrate the use of the search engine. Section
5 shows how visualization can be utilized to better
understand the retrieved results. It also describes the focus+context view of
Web nodes. Finally, section 6 is the conclusion.
There are many popular Web search engines like Lycos [18]
and Alta Vista [13]. These engines gather textual
information about resources on the Web and build up index databases. The indices
allow the retrieval of documents containing user-specified keywords. Another
method of searching for information on the Web is subject-based directories
which provide a useful browsable organization of information. The most popular
one is Yahoo [20] which classifies documents manually and
supports content-based access to the collection of documents gathered from
either users' submission or Web robots. However, none of these systems allows
image search.
Searching for similar images from an image database is a developing research
area. Some popular image retrieval systems like QBIC [4]
and Virage [1] have demonstrations running on the
World Wide Web. These systems retrieve all images from an internal database
that are visually similar to a user-specified image. The similarity is
determined by properties like color and shape. QBIC integrates keyword search
also. However, finding similar images from any arbitrary Web site is not
possible. Yahoo's Image Surfer [17] has built a collection
of images that are available on the Web. The collection is divided into
categories (like automotive, sports, etc), allowing the users to find images
that match the category keywords. However, HTML document search is not
integrated. Moreover, although the user can retrieve images that are similar to
a selected image, the image-searching mechanism is quite simplistic - it is
based on just color histogram. Webseer [5] is a crawler
that combines visual routines with textual heuristics to identify and index
images on the Web. The resulting database is then accessed using a text-based
search engine that allows users to describe the image that they want by using
keywords. This approach of retrieving images is complementary to our approach.
In AMORE the user can specify an image and retrieve all images similar to it. Of
course, the user can also specify keywords to retrieve Web documents (and the
images in them).
While none of the current search engines support visualization of the results,
several visualization systems for information retrieval have been developed in
recent years. Examples include Infocrystal [12], an
extension of the Venn-diagram paradigm, which allows the visualization of all
possible relations among N user-specified Boolean keywords, Tilebars
[6], a visualization method for term distribution in Full
Text Information Access and Butterfly [8], an information
visualization application for accessing Citation databases across the Internet.
These systems show the usefulness of visualization for better understanding of
the results of search engines. Another interesting approach is the WebBook
[3], which potentially allows the results of the search to
be organized and manipulated in various ways in a 3D space.
Implementing a search engine involves two phases: indexing and querying.
Several systems exist that allow full-text indexing of Web sites. The indices
allow the user to search the indexed sites using any combination of keywords.
As stated in the previous section, systems that can index images in a database
based on various image characteristics like shape and color, thus allowing the
retrieval of images in the database that are similar to a user-specified image
are also being developed. In AMORE we have integrated these into two kind of systems
in a unique way. This allows the retrieval of Web documents containing one or
more keywords and/or images similar to an user-specified image. While we use
the Harvest Information Discovery and Access System
[2] for text indexing and searching, we use the
content-oriented image retrieval (COIR) library [7]
for image retrieval. This section explains the indexing and querying techniques.
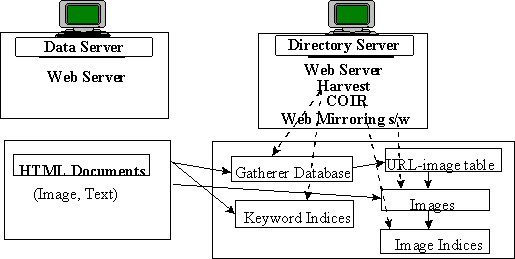
Figure 1. The indexing mechanism in AMORE. Harvest is used for
indexing the data servers, a Web mirroring software downloads the images and
then COIR indexes the images.
Figure 1 describes the indexing mechanism. In the
directory server, a Harvest gatherer is used to gather and index
textual information from the user-specified sites. The user is allowed to
specify one or more sites by listing their URLs. Moreover, Harvest allows the
indexing of only a section of a site by various mechanisms (for example,
limiting the URLs that are indexed by using regular expressions). After Harvest
has finished gathering, information on the images that are contained in and
referenced from each HTML page is available from the gatherer's database in the
directory server. A PERL program extracts this information and creates a
URL-image table. The images are then downloaded to the directory server using a
Web mirroring software. Then COIR is used to index all these images.
COIR uses a region-based approach and uses attributes like color, texture, size
and position for indexing. The whole indexing procedure is automated requiring
the user to just enter some required information (like the URLs of the sites
that are to be indexed). Note that while the Harvest gatherer may take a long
time for indexing large sites, creating the URL-image table and indexing the
images take a comparatively shorter time. COIR requires about 5 seconds to
index an image. Also note that the images can be removed from the directory
server after the indexing if there are space constraints.
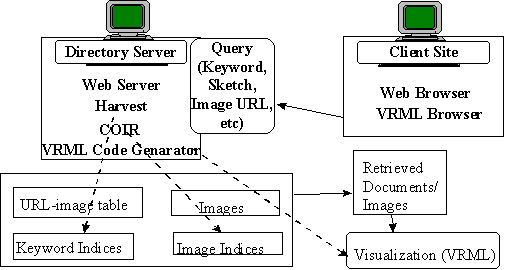
Figure 2. The querying mechanism in AMORE. The query may
contain both keywords and an image. Harvest and COIR are used for retrieving
the documents matching the specified query. Visualization of the search results
are possible.
After the text and image indices have been built into the server, users on any
client can issue queries. Figure 2 explains the querying
phase. The queries can contain one or more keywords or an image. The text and
image search can also be combined by and or or. The user can
specify the image in various ways: for example, by specifying its URL or by
drawing a rough sketch. The Harvest broker is used to retrieve
documents that contain the user-specified keywords. The broker provides an
indexed query interface to gathered information. To accommodate diverse
indexing and searching needs, Harvest defines a general broker-indexer
interface that can accommodate a variety of search engines. We are using
glimpse as our search engine.
COIR is used to retrieve images available on the indexed Web sites that are
similar to the user-specified image. Similarity is determined by both
color (the general color impression of the image) and shape
(the number of regions in the images that correspond to each other and the
similarity of shape and position between the matched regions). Each indexed
image is given a match rate which is a combination of its shape and
its color match rate. Images with a total match rate that is greater than a
threshold value are selected and the documents containing them are
retrieved. The user has the option of changing the threshold value to control
the number of images that are retrieved. She can also change the
color-shape ratio which determines the importance that is given to
color and shape similarity.
If the text and image search are combined by and, only documents that
are retrieved by both the text and image search are displayed to the user;
otherwise all retrieved documents are displayed. The retrieved documents are
displayed sorted by the number of keyword matched lines. The user can also view
the retrieved images sorted by the total match rate. Various ways of
visualizing the search results are possible. These issues are discussed in the
next two sections. Note that although a precise performance analysis of the
querying phase is not possible because of potential network delays, we have
found that image search is faster than text search and the overall performance
is quite satisfactory.
We have indexed several Web sites allowing us to query these sites based on
both images and keywords. This section presents some sample retrieval
scenarios from two Web sites to show the usefulness of the technology.
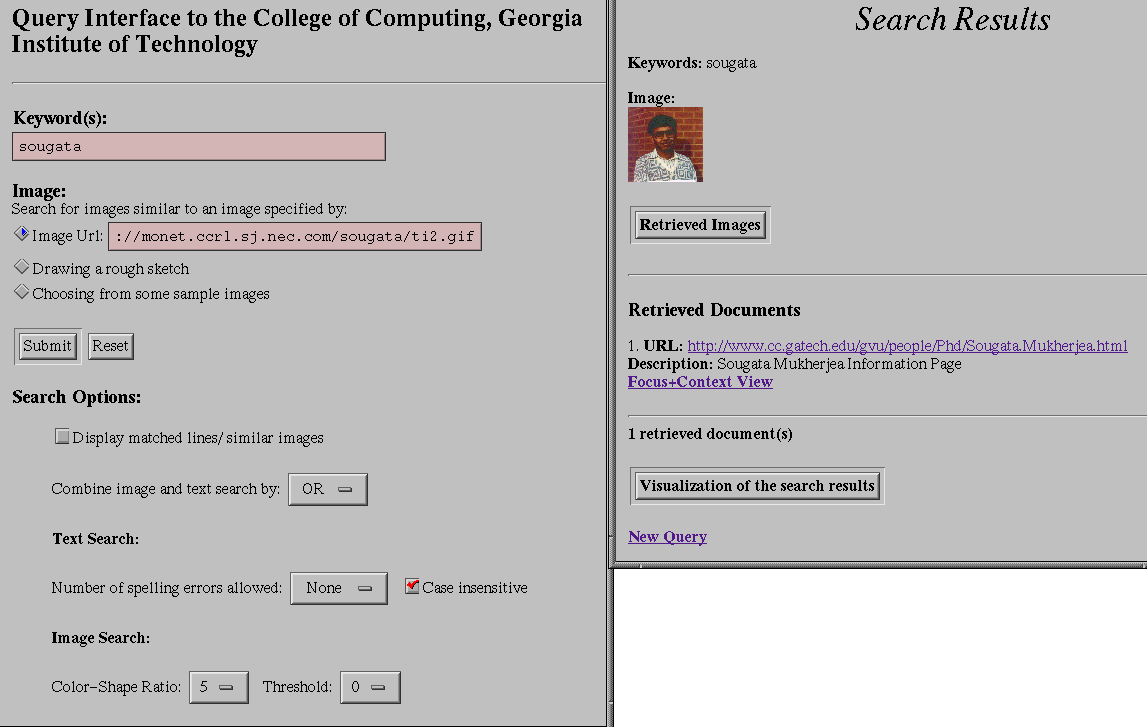
Figure 3. The right hand side shows the interface to the
search engine. The user can specify keywords and the URL of an image. Various
search options can also be changed. Here the user is trying to retrieve the
homepage of the first author from the Georgia Tech College of Computing Web
server. The search result is shown on the right.
4.1.1 Searching for a particular document.
One common use of a search engine is to find someone's homepage. If we just use
the person's name as keyword, sometimes lots of other pages are also retrieved.
The person's photo can be used to reduce the number of irrelevant
documents. The left-hand side of Figure 3 shows the
interface to the search engine. The user is trying to retrieve the homepage of
the first author of this paper from the Web site (he was a student there) using
his name"sougata'' as the keyword and the URL of his photograph which is
stored in the client site. Notice that there are various search options (like
the color-shape ratio) that can be changed. The query retrieves the required
homepage as shown in the right-hand side of Figure 3.
4.1.2 Searching for a class of documents.
AMORE is also useful for gaining an understanding on a particular topic from a
Web site. For example, suppose the user wants to find information about all
information visualization projects in the college. Since many project
descriptions may not explicitly use the words "information" and
"visualization," using only the keywords may not be enough. Moreover, the
user may want to also retrieve images of the screen dumps of the projects if
they exist on the Web. An image of a window dump of an information
visualization project may be helpful in this case. The left-hand side of Figure
4 shows the result of searching the Web server combining a
text search (by the keywords "information visualization") and an image search
(with an image of a window dump of an information visualization project) by
"or." The retrieved documents are sorted by the number of keyword-matched
lines. The user can also look at the retrieved images as shown in the right-hand
side of Figure 4. They are sorted by their similarity to the
given image. All of the images are window dumps of similar projects. (Note that
only the first few documents and images are shown in this figure).

Figure 4: The left-hand side lists the documents retrieved by
a text search with keywords "information visualization" combined by "or"
with an image search of an image of a window dump of an information
visualization project. The right-hand side shows the retrieved images.
4.2.1 Media-based Navigation:
The user may select a sample image from the site and retrieve all
other images similar to it. The interface for choosing the image is
shown in the left-hand side of Figure 5; some
images from the site are randomly selected and shown to the user. Here
the user is trying to retrieve pictures of scenes from Walt Disney
movies. Therefore the keyword "movie" and a similar image, that of a
movie scene, is used. Some movie clips are retrieved as shown in the
middle of Figure 5. The user can click on one of
these images and retrieve more similar images. The images retrieved by
the second query are shown on the right-hand side of Figure 5. This type of navigation where the user uses the
same type of media for a query as the media they want to retrieve is
known as media-based navigation [7].
Note that in this case the use of keywords in combination with the
media-based navigation allowed the filtering of pictures similar to
the query image from the image-processing point of view but which do
not have anything to do with movies. (Although some irrelevant
pictures may still be retrieved because the documents containing them
haver the query keyword, the combination of text and image search
helps to reduce the number of irrelevant documents that are
retrieved).
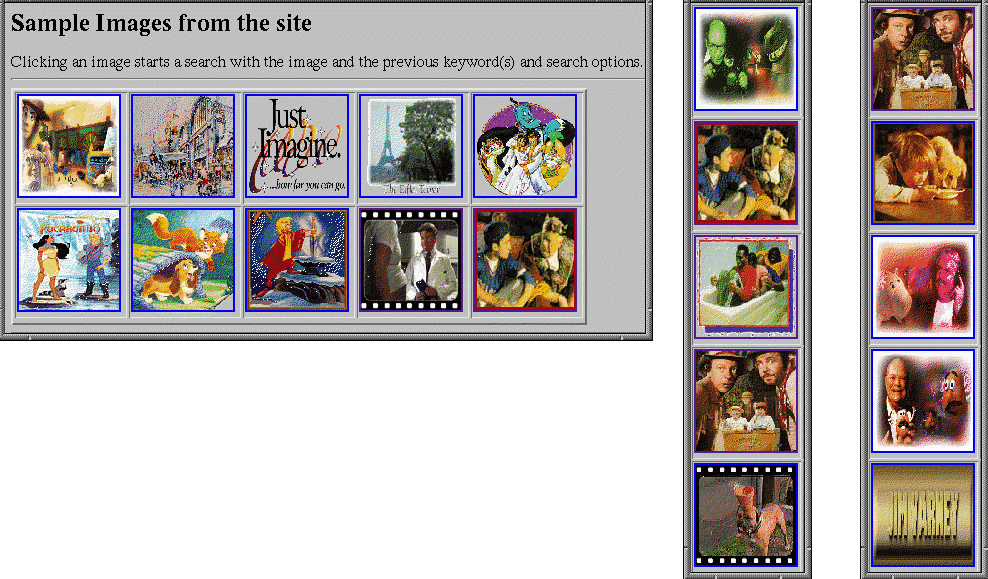
Figure 5. Example of media-based navigation. The user is
searching for movie clips from the Walt Disney Web site by using a similar
image. Text search is also combined with the image search (by and).
4.2.2 Rough Sketch Input. Suppose an user wants to retrieve
images of Mickey Mouse from the Disney Web site. If no picture of
Mickey Mouse is available, the user can draw a rough sketch to
retrieve the pictures. The rough sketch interface is implemented using
Java and shown in the left-hand side of Figure 6.
The right-hand side of the figure shows the images that are retrieved
for the given rough sketch. Some images of Mickey Mouse are retrieved
as the user wanted.
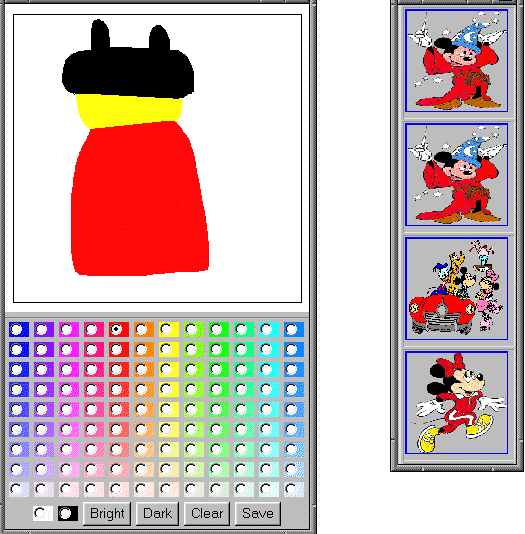
Figure 6. The left-hand side shows the interface for inputting
a rough sketch. The right-hand side shows some images that are retrieved for the
given rough sketch.
Unfortunately, most popular Web search engines do not provide any
visualization; the retrieved records are displayed as one or more pages of
scrolled lists. If many records are retrieved, scrolling through such lists is
tedious. Visualization may be useful in this case. Visualization is especially
useful for multimedia search because the searching is based on various criteria
like the number of keyword-matched lines for text search and shape and color
similarity for image search. Showing how the retrieved documents compare based
on the various search criteria in a single screen is useful. Therefore, we
provide various kinds of visualizations of the results of the search. The
visualizations are generated from the search results on the fly by a perl
program which generates Virtual Reality Modeling Language (VRML) code.
They can be viewed in a browser that supports VRML. We have used SGI's
Cosmo Player [15] both on a SGI workstation and a PC as the
VRML browser. Various kinds of visualizations are available and some significant
ones are discussed in this section.

Figure 7. A scatter-plot visualization of the search results.
Shape and color similarity are mapped to the X and Y axis. Documents with same
images are arranged in the Z axes. Size is mapped to keywords. The left-hand side is the
overview. In the right-hand side the user has zoomed in to the document with the maximum
keywords.
The left-hand side of Figure 7 shows a scatter-plot
visualization of the results of a search of the Georgia Tech College of
Computing server. The search criterion was the one used for Figure
4. In this visualization a cube represents each retrieved
image. The shape-match rate (how well the image matches the selected image based
on just shape) has been mapped to the X axis and the color-match rate to
the Y axis. Documents with no similar image are also shown; they are
assumed to have the minimum values for x and y and are shown at the
bottom right. In many cases, the same picture (for example logos of
organizations) exists in many Web pages. Since all these images will have the
same values for x and y, they are arranged in the Z
dimension. The sizes of the cubes indicate the number of keywords in the
corresponding documents and the colors represent the topic of the pages (the
topic is determined from the URL; for example, a document with URL
www.cc.gatech.edu/gvu/.... has topic gvu). The cubes also
serve as links; moving the cursor over them displays the URLs of the
corresponding documents and clicking on them retrieves the actual documents.
The user can change the bindings between the visual and information attributes
in a Forms interface.
The visualization gives the user a better understanding of the search results.
The user can see how the retrieved documents compare based on the various
criteria in the same screen without having to switch between two screens, one
sorted by the text search criteria and one by image search criteria (as shown
in Figure 4). Moreover, how well the retrieved images
match the given image based on just shape or color is evident. Obviously,
documents on the top-left corner are very similar images having large values
for both x and y. The user can use the various tools provided by
the VRML browser to navigate through the space. Various viewpoints are also
provided to allow the user to zoom in on different important positions in the
space. For example in the right hand side of Figure 7 the
user has zoomed in to the document with the maximum number of keywords and is
navigating through the 3D neighborhood. Note that the actual image which the
cube represents is shown only when the user comes close to a cube (since texture
mapping is expensive if it is not supported by the hardware).
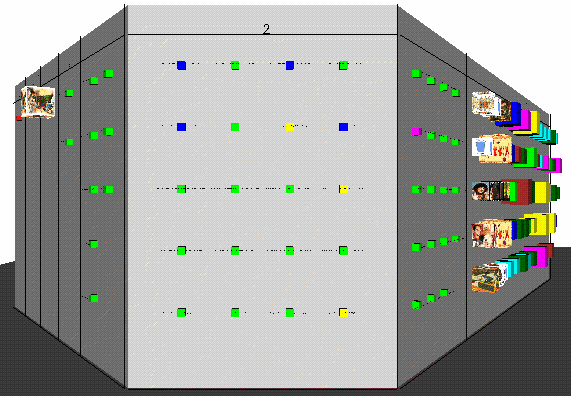
Figure 8. A perspective wall visualization. Each wall contains
documents with similar numbers of keywords. The sizes of the cubes represent the
similarity of the images in the documents to the user-specified image.
Figure 8 shows a perspective wall [9]
visualization of the results of a search. Here the Walt Disney Web site was
searched for documents with the keyword "toy story" or images similar to a
scene from that movie. The retrieved documents are represented by cubes and then
grouped by the number of keyword-matched lines and arranged on walls. The walls
are sorted by the number of keywords in the documents on them. One wall is in
focus at a time and the user can click on any wall to bring it in to focus. Smooth
animation is used for the state changes (using Javascript in combination with
VRML 2.0). The sizes of the cubes are mapped to the total match-rate (that is, the
overall similarity) of the image contained in the document and shown as a
texture map. If there are no images, the cubes have minimum size. On the other
hand, if there are n images, n cubes are used to represent the
document.
While the current search engines show the Web pages that match the user's
queries, they don't give any indication of the actual position of the page in
the Web site from which it was retrieved. Therefore, we have developed a
technique to show focus+context views of Web documents. The view shows the
details of a particular node; nodes in the immediate neighborhood, those that
can directly reach and can be reached from the document are shown. While the
local detail is useful, the user also needs to understand the global context.
Since any real-world Web site has a large and complicated network structure, to
simplify the view the paths to and from the important (landmark) nodes
in the Web site are only shown. This is similar to a common geographical
navigation strategy: a lost person will try to find where she is using her
immediate neighborhood and important geographical landmarks. The landmarks are
determined using various heuristics like connectivity (how well a node
is connected to other nodes) and access frequency (how many times the
node has been accessed in recent times). The procedure for determining landmark
nodes and developing the focus+context views is explained in detail in
[11].
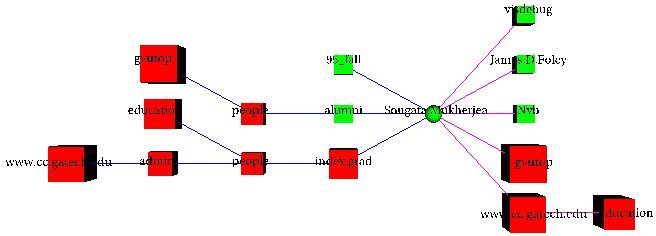
Figure 9. Focus+Context view of the homepage of Sougata
Mukherjea in the College of Computing Web server. It is useful in understanding
the first author's position in the college.
Figure 9 shows the focus+context view of the homepage of
the first author of this paper which was retrieved by the query of Figure
3. This view shows the immediate neighborhood of the
node as well as the shortest paths from several landmark nodes in the College of
Computing Web site (depicted by red) like gvutop. Size indicates the
importance of the node in the Web locality. The view is quite useful in
understanding the position of Sougata in the College. Since there is a path from
alumni, it shows that he is an alumnus of the College; a path from
index.grad indicates that he was a graduate student and the path from
gvutop means that his research was in the gvu (Graphics, Visualization
& Usability) area. Moreover, some related nodes (like the homepage of his
advisor, James.D.Foley, and pages describing some projects that he had
worked on, Nvb and visdebug) can be seen. Note that clicking
on the node whose view is being shown (depicted by a sphere) retrieves the
actual page while clicking on some other node (depicted by cubes) retrieves the
focus+context view of that page. This allows the user to quickly gain an
understanding of the section of the Web that is of interest.
In this paper we have presented AMORE, a Web search engine that provides several
unique features not present in the current Web search engines.
- We allow the automatic indexing of both text and image from one or more Web
sites. This integration of text and image search is useful in various retrieval
scenarios:
- When the user is searching for Web documents, the combination of
text and image search by and can reduce the number of irrelevant
documents that are retrieved.
- On the other hand, the combination of text and image search by or
can increase the number of retrieved relevant documents.
- The user can also search for images on the Web by specifying a similar
image. By combining text search also, the user may reduce the number of
irrelevant images retrieved.
- Visualizations of the search results allow the user to understand the
results better.
- The focus+context view of a Web node helps in understanding the position
of the node in the Web site from which it was retrieved.
We are currently working on the first publicly available version of AMORE
[14]. In this version, several Web sites containing
various categories of images will be indexed. Our technique will allow the
searching of these sites based on both images and keywords.
Future work is planned in various directions. The visualizations need to be
improved based on usability studies. Then we plan to make the visualizations
publicly available. At present we are also working on video retrieval. The
architecture of AMORE will allow the integration of video indexing and searching
with minimal effort. We also want to integrate a browsing environment like the
one provided by Navigational View Builder [10]
into our search engine. This will allow the user to browse through a Web site
of interest to see what is available. We believe that a multimedia information
retrieval engine will enhance the usefulness of the World Wide Web by reducing
the lost in hyperspace problem.
References
- 1.
-
J. R. Bach, C. Fuller, A. Gupta, A. Hampapur, B. Horowitz, R. Jain, and C. Shu.
The Virage Image Search Engine: An Open Framework for Image
Management.
In Proceedings of the SPIE - The International Society for
Optical Engineering: Storage and Retrieval for Still Image and Video
Databases IV, San Jose, CA, USA, Feb. 1996.
- 2.
-
C. Bowman, P. Danzig, D. Hardy, U. Manber, and M. Schwartz.
The Harvest Information Discovery and Access System.
In Proceedings of the Second International World Wide Web
Conference, Chicago, Illinois, October 1994.
- 3.
-
S. Card, G. Robertson, and W. York.
The WebBook and the Web Forager: An Information Workspace for the
World Wide Web.
In Proceedings of the ACM SIGCHI '96 Conference on Human Factors
in Computing Systems, pages 112-117, Vancouver, Canada, April 1996.
- 4.
-
M. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang, B. Dom, M. Gorkani,
J. Hafner, D. Lee, D. Petkovic, D. Steele, and P. Yanker.
Query by Image and Video Content: The QBIC System.
IEEE Computer, 28(9):23-48, September 1995.
- 5.
-
C. Frankel, M. Swain, and V. Athitsos.
WebSeer: An Image Search Engine for the World Wide Web.
Technical Report 96-14, University of Chicago, Computer Science
Department, August 1996.
- 6.
-
M. Hearst.
Visualization of Term Distribution Information in Full Text
Information Access.
In Proceedings of the ACM SIGCHI '95 Conference on Human Factors
in Computing Systems, pages 59-66, Denver, CO, May 1995.
- 7.
-
K. Hirata, Y. Hara, N. Shibata, and F. Hirabayashi.
Media-based Navigation for Hypermedia Systems.
In Proceedings of ACM Hypertext '93 Conference, pages 159-173,
Seattle, WA, November 1993.
- 8.
-
J. Mackinlay, R. Rao, and S. Card.
An Organic User Interface for Searching Citation Links.
In Proceedings of the ACM SIGCHI '95 Conference on Human Factors
in Computing Systems, pages 67-73, Denver, CO, May 1995.
- 9.
-
J. D. Mackinlay, S. Card, and G. Robertson.
Perspective Wall: Detail and Context Smoothly Integrated.
In Proceedings of the ACM SIGCHI '91 Conference on Human Factors
in Computing Systems, pages 173-179, New Orleans, LA, April 1991.
- 10.
-
S. Mukherjea and J. Foley.
Visualizing the World Wide Web with the Navigational View Builder.
Computer Networks and ISDN Systems. Special Issue on the Third
International World Wide Web Conference, Darmstadt, Germany,
27(6):1075-1087, April 1995.
- 11.
-
S. Mukherjea and Y. Hara.
Focus+Context Views of World Wide Web Nodes.
To appear in Proceedings of ACM Hypertext '97 Conference, Southampton,
England, April 1997.
- 12.
-
A. Spoerri.
InfoCrystal: A Visual Tool for Information Retrieval and
Management.
In Proceedings of Information and Knowledge Management '93,
Washington, D.C., November 1993.
Relevant URLs
- 13.
-
Alta Vista http://www.altavista.com
- 14.
-
AMORE
http://www.ccrl.neclab.com/amore
- 15.
-
Cosmo Player
http://vrml.sgi.com
- 16.
-
Georgia Institute of Technology College of Computing
http://www.cc.gatech.edu
- 17.
-
Image Surfer
http://isurf.yahoo.com
- 18.
-
Lycos
http://www.lycos.com
- 19.
-
Walt Disney
http://www.disney.com
- 20.
-
Yahoo
http://www.yahoo.com
Return to Top of Page
Return to Technical Papers Index