
Clairmont Borges, José Valdeni de Lima
Instituto de Informática - UFRGS - Porto Alegre,
RS, Brazil
Antônio C.Rocha Costa
Instituto de Informática - PUCRS - Porto Alegre,
RS, Brazil
clermont@inf.ufrgs.br, rocha@inf.pucrs.br, valdeni@inf.ufgs.br
This work proposes Services to Aid Information Consumption (SAIC) in the WWW. SAIC constructs an Information Market (InfoMarket) with Information Niches hierarchically organized by topics and physically replicated. In this InfoMarket, not only Consumers can search for Providers, but also Providers can search for Consumers. The InfoMarket contains Meta-Information mapped from Providers, who supply information, and Consumers, who demand information. Applications Systems (like search engines and filtering tools) can develop services using the low cost Meta-Information available in the InfoMarket Niches. SAIC reuses some ideas of the Harvest System project [1] and incorporates new ones in order to efficiently construct and maintain the InfoMarket Niches.
Keywords: Internet, World Wide Web, Resource Discovery, Information Filtering, Information Dissemination, Harvest System.
We first define our concept of Information Consumption (InfoCons). Part of the InfoCons scenery is composed of an Information Space constituted by supply information from Providers and demand information from Consumers. The InfoCons is realized when the Consumer: (1) knows what is the information of interest; (2) finds the Provider where the information of interest is stored; and (3) accesses this Provider and gets the information of interest. Another part of the InfoCons scenario is composed of Meta-Information mapped from the Information Space by Facilitators. Facilitator is a provider of Meta-Information and services that aid the Consumer to realize the InfoCons. Some known examples of Facilitators are AltaVista [2], Yahoo [3], Inference [4], Lycos [5], InfoSeek [6], Excite [7].
The concept of InfoMarket is similar to the Newsgroups information space: logically it is organized in a hierarchy of topics and physically it is replicated. Other similarities between the InfoMarket and Newsgroups are: (i) Providers and Consumers have the initiative to respectively send supply information and demand information; (ii) Facilitators and many other application systems can develop InfoCons services there.
For didactic purposes, we consider the Consumer navigation in the WWW similar to packets routing in the Internet transport layer. The Consumer can "route itself" by deciding, in the accessed WWW pages, what existing hyperlink will be followed; and/or the Consumer can also use Facilitators "route services", i.e. the Facilitators Meta-Information and services that aid the InfoCons. Packets routing reaches scalability by permitting autonomous updates at autonomously managed sites, is fault-tolerant (considering the multiple routing paths available), and is reliable because all sites follow a standard of IP address and Domain Name Service (DNS).
We consider the "Consumer routing" as vital as packets routing. We believe that Facilitators need to be aided by services that operate in a distributed fashion and whose management is decentralized, in order to reach scalability and then reduce costs in terms of server load and network traffic. So, we propose here the SAIC, grouped in three basic services:
Gathering: detects changes in the InfoCons Information Space and send Meta-Information concerning these detected changes to the Information Market;
Filtering: receives Meta-Information from the Gathering service and filters the Meta-Information to the appropriate Niches;
Dissemination: concerns to replication, caching, and transmission of information flows inside the Information Market.
This paper proceeds as follows. Section 2 reviews the information systems that implemented the idea of Information Market. Section 3 describes the SAIC information model. Section 4 describes the basic services of Gathering, Filtering, and Dissemination. Section 5 comments about implementation issues. Section 6 concludes this paper. Throughout the paper, related work is discussed as relevant.
We comment here, under the InfoMarket perspective: the Newsgroups, the Harvest System, Netscape's approach with one product and Yahoo's service.
Newsgroups is the information system precursor of the InfoMarket concept. Its information space is organized in a hierarchy of topics and is replicated to improve users access. Newsgroups users (Providers, Consumers) have the initiative to access (normally the nearest) News server, select the groups of interest (i.e. focus the InfoMarket Niches of interest), and then consume or provide information. As the Newsgroups database increased so much, users started to use Facilitators services.
A known example of Facilitator that provides InfoCons services in the Newsgroups is the Stanford Information Filtering Tool (SIFT) [8]. SIFT allows newsgroups users to subscribe profiles that specify their information of interest. The subscriptions are stored in a database and as the SIFT server receives new information from Newsgroups servers, the SIFT filtering engine processes the new information against the subscriptions database, and then SIFT sends to users the information that matched their profiles.
A problematic issue in the Newsgroups is the lack of automatic services to control the information posting when a user (intentionally or not) posts an information whose content does not match to the group(s) topic (i.e. does not belong to the group semantic domain). The misplaced information in a group creates inconsistencies in its information space, and these inconsistencies are propagated to the Meta-Information generated (e.g. index structures) by Facilitators that are providing InfoCons services in this group.
The Harvest System is a Facilitator that coordinates its subsystems efforts in order to provide InfoCons services. The Gatherer [9] subsystem collects and summarizes Providers Information. (Providers can cooperate by running the Gatherer locally, which improves efficiency.) The Gatherer exports the summarized information to one or more Brokers [10] subsystems. The Broker stores and controls the summarized information and provides a query interface to Consumers (including others Brokers). The Index/Search [11] subsystem indexes the Broker summarized information and executes searching operations. The Broker has a general Indexer Interface that can accommodate a variety of indexers (e.g. WAIS [12], Nebula [13], Verity [14], GRASS [15]). Brokers can construct views over the space of summarized information by submitting queries to others Brokers.
This allows the construction of a hierarchy of topic specific Brokers (implementing the InfoMarket concept) like the Newsgroups hierarchy, except that here the summarized information space is more consistent because it is constructed with search queries that operate on the summarized information content. In the hierarchy of topics specific Brokers, Providers and Consumers can select the topic specific Brokers of their interest in order to respectively send supply information (the summaries) and demand information (the queries).
The Harvest also has the Replicator [16] subsystem, which creates and manages Brokers replicas, minimizing the load on most accessed Brokers. The Replicator measures the available bandwidth in the Replicas group and then computes a logical topology over which to send updates. This offloads logical topology decisions from the Replicator administrators, while Newsgroups administrators have to hand-configure their logical topology of updates. Finally, there is the Object Cache [17] subsystem that caches the information that Consumers most access in the Providers. The Harvest System is discussed with more detail in section 4, where improvements are proposed to specify the SAIC.
During a study of some Facilitators [18], we have found some similarities between Yahoo and Harvest services:
They give support to Providers to give their information content. Yahoo allows Providers to input their information into Yahoo's hierarchy of searchable topics, via a WWW forms interface. Harvest allows Providers to export their information summaries by subscribing to a Gatherer subsystem (which may run local or remotely);
They both have replication to diminish overload on most accessed servers;
They have similar but symmetrical InfoCons perspectives: Perspective Consumer-Provider (PC-P) and Perspective Provider-Consumer (PP-C), (see Fig.1).
The PC-P views the InfoMarket from Consumers to Providers, where the Consumers look for the Providers supply information. Yahoo uses the PC-P by allowing Consumers to browse its hierarchy of searchable topics, from more-general topics to more-specific topics, until Consumers reach the exact topic where they submit search queries.
The PP-C views the InfoMarket from Providers to Consumers, where the Providers supply information look for "Niches of Consumers". Harvest uses the PP-C by allowing Providers to subscribe or install Gathering services of information extraction and summarization. The summaries are exported to Brokers of more-general topics, where Brokers of more-specific topics submit search queries to retrieve only the specific information of their topics. Consumers (including others Facilitators) can search any Broker that composes the hierarchy of topic-specific Brokers.
They both have Netscape's interest. In the end of 1995, the Harvest research project ramped down and Harvest ideas moved to software industries [19]. Netscape has developed a product named Netscape Catalog Server - which is based on Harvest System Project [20]. Netscape has also, associated in 1995 with Yahoo, moved Yahoo's databases from Stanford University to Netscape computers [21].
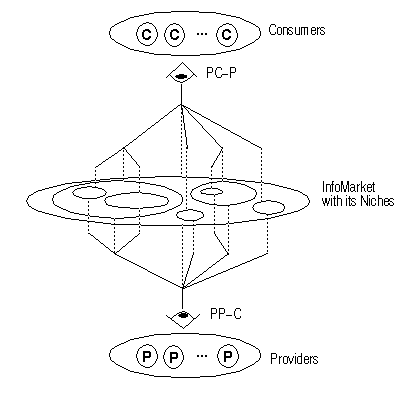
Fig.1 Perspectives PC-P and PP-C
Before describing the Services to Aid Information Consumption (SAIC), we explain some SAIC extensions to the Providers, Consumers and Information concepts.
A Consumer also acts as a Provider of data (e.g. the search queries submitted to search engines like AltaVista, the filtering queries stored in filtering engines like SIFT, the log data generated during servers access). These data can be processed to generate useful information (as in Data Mining Services).
A Provider can become a Consumer when it is interested in discovering, for example, who is consuming its supply information, what are the other preferences of its Consumers, or who and where are the potential Consumers of its new supply information. When a Provider looks for such information, it switches its role from Provider to Consumer.
The following example illustrates these InfoCons concept extensions:
We described in section 2 that SIFT is a Facilitator that allows users to subscribe to profiles that specify what kind of information SIFT has to filter from Newsgroups and send to these users. Suppose that SIFT creates a new service: it indexes the user profiles database, and then provides a search engine service with these indexes. This would allow Providers to discover users interest in a certain subject or topic. When SIFT users subscribe their profiles, they act as Consumers of the filtering engine service - but they act as Providers to the new search engine service.
The SAIC considers that the information in the InfoMarket can be either supply information or demand information. They each have three possible representations in the InfoMarket:
Now, we respectively describe the SAIC Gathering, Filtering and Dissemination Services.
The SAIC Gathering service feeds the InfoMarket with MetaInfo. The SAIC Gathering monitors the Provider's InfObjects space in order to detect modifications in this space (e.g. InfObjects creations, updatings or deletions). MetaInfos are generated for the modified InfObjects and are exported to the InfoMarket.
The use of MetaInfo in the InfoMarket have the following advantages:
(1) Because they are "condensed", they save storage space in the information systems and bandwidth in the communication lines;
(2) Because they are composed by the most representative InfObjects content, they have more semantic precision.
The SAIC Gathering includes the services of the Harvest Gatherer Subsystem and includes a new one: Providers discovery. The Harvest System divides the Provider's space by network subdomains and in each network subdomain the gathering is done by a Gatherer Subsystem. In the Harvest System, the inclusions of new Providers in the gathering service have to be hand-configured by the Gatherer Subsystem administrators. The new gathering service proposed by the SAIC Gathering is the monitoring of the DNS of the network subdomain where the SAIC Gathering is operating, so new Providers addresses can be discovered automatically. With this new service, SAIC Gathering administrators are notified about the newly discovered Providers and they decide whether these new Providers are included or not in the gathering service.
In each network subdomain covered by a SAIC Gatherer there is also a Broker (with similar functionalities like those provided by a Harvest's Broker). This network subdomain Broker (NS-Broker) stores the MetaInfo generated by the SAIC Gatherer. As in the Harvest System, each SAIC component (e.g. Gatherer, Broker) is registered in a Master Broker of SAIC - whose information is useful when installing new SAIC components, to avoid effort duplication. Fig.2 illustrates the SAIC Gathering service in the InfoMarket scenery.
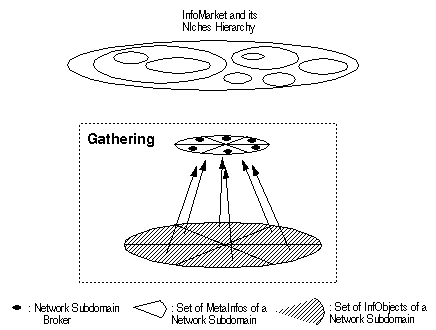
Fig.2 The SAIC Gathering Service
In the worst case, the SAIC Gatherer operates remotely on the Provider's servers that still don't have a local SAIC Gatherer service. In the best case, the Provider has a local SAIC Gatherer service, with the advantages of: (a) determining the best period and way that MetaInfo are generated, and (b) compressing the MetaInfos in a single file, which is exported via a single connection. Providers that have the local SAIC Gathering service contribute to diminishing the problem of "Copy Detection and Elimination" (this problem is described with more details in [22]), because the Provider determines only the monitoring of its own InfObjects - not the InfObjects that are replicated from others Providers.
Another possible service, if the Provider has the local SAIC Gathering, is to move a deleted InfObject to a temporary InfObject, and generate a notification MetaInfo that represents this InfObject and its deleted status. Only the InfoMarket appropriated Niches receive this notification MetaInfo (this is described in the SAIC Filtering service). The temporary InfObject has an expiration time which is the same for its notification MetaInfo, so they are simultaneously removed from the Provider's server and from the appropriated Niches. The MetaInfos that represent the deleted InfoObject are removed from their respective Niches when the notification MetaInfos arrive there. During the life period of the temporary InfoObject, the InfoMarket information systems that have links to the deleted InfObject can make a physical copy of it.
Thus, the use of the SAIC Gathering service has many advantages, but the biggest one is its scalability: the Provider's InfObjects Space is gathered incrementally - by default, the SAIC Gathering generates MetaInfo only for the modifications (InfObjects creation, updating, or deletion).
The SAIC Filtering Service receives MetaInfos from the SAIC Gathering service and filters the MetaInfos to the appropriate Niches inside the InfoMarket hierarchy of Niches. In the InfoMarket, a new Niche can be either a specialization of another existing and more generic Niche, or a first-level Niche in the hierarchy. The "root" Niche of the hierarchy is distributed and is stored by the set of NS-Brokers.
Each Niche in the hierarchy has at least one Broker to store the Niche's MetaInfos. It is called "more specific Niche" (Niche+S) the Niche that is a specialization of another existing and "more generic Niche" (Niche+G). When a Niche+S is created, the Broker of the Niche+S (BrokerN+S) subscribes a filtering query in the Broker of the Niche+G (BrokerN+G). If the new Niche is a first-level Niche in the hierarchy, then it subscribes a filtering query in each NS-Brokers (as we will see in the SAIC Dissemination service, a new first-level Niche can also subscribe its filtering query to only one NS-Broker, which disseminates this query to the others NS-Brokers). When a BrokerN+G filters a MetaInfo to a BrokerN+S, the BrokerN+G makes a copy of this MetaInfo to the BrokerN+S. Fig.3 illustrates the SAIC Filtering Service in the InfoMarket scenery.
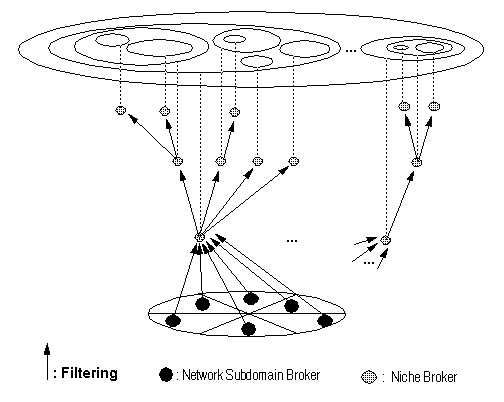
Fig.3 The SAIC Filtering Service
The Harvest System constructs its hierarchy of topic-specific Brokers using search operations performed by the Harvest Index/Search Subsystems. Now, the SAIC constructs the InfoMarket hierarchy of Niches using filtering operations - which are more efficient in this InfoMarket context. The Fig.4-a and Fig.4-b illustrate respectively the Harvest's search operation and the SAIC's filtering operation - each operating in a sub-tree of the hierarchy.
Two important characteristics of the InfoMarket scenery determine the efficiency of the SAIC's filtering operation: (1) the hierarchy of Niches is quite stable (like Newsgroups hierarchy), and (2) the information gathering is incremental (the InfoMarket is fed with only the modifications of the Provider's InfObjects Space).
As described in [22] and [23], search and filtering operations are "symmetrical": In the search case, a query is received and checked against an index of documents (here, "documents" are InfObjects or MetaInfos); in the filtering case, a document is received and checked against an index of queries.
In the Harvest's topic-specific hierarchy construction, the Brokers of more specific topics submit search queries to the Brokers of more generic topics. Considering the situation illustrated in Fig.4-a, the total cost of the Harvest's Index/Search subsystem is composed of two main costs:
In the SAIC's Niches hierarchy construction, the BrokerN+S subscribe their filtering queries in the BrokerN+G. Considering the situation illustrated in Fig.4-b, the total cost of the SAIC Filtering Service is composed of two main costs:
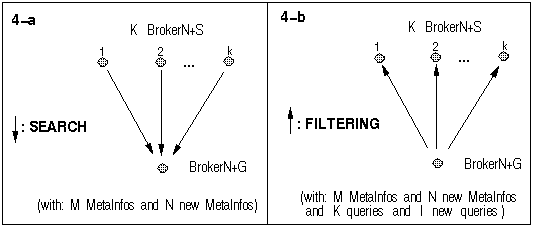
Fig.4 Harvest's search operation and the SAIC's filtering operation
Both the hierarchy of topic-specific Brokers constructed by Harvest, and InfoMarket Niches hierarchy constructed by SAIC receive MetaInfo incrementally. In both hierarchies, the "cell" is a sub-tree (as illustrated in Fig.4-a and Fig.4-b). The filtering operation is more efficient than the search operation because:
Thus, the SAIC use Filtering Services operating in the BrokerN+G in order to content route the MetaInfo in the InfoMarket Niches Hierarchy. Therefore, the SAIC reach scalability both in the Gathering and Filtering Services, because they both operate incrementally.
One advantage of this approach is the fact that a MetaInfo keeps stored in the BrokerN+G (even when a MetaInfo is filtered to a BrokerN+S, one copy is made to the BrokerN+S). If a MetaInfo is not filtered to others BrokerN+S (because their filtering queries do not match it), this MetaInfo keeps stored in the Niche (precisely, in the BrokerN+G) and can be discovered and retrieved by Facilitators services (like AltaVista, Yahoo, etc). This MetaInfo that is not immediately matched with the existing filtering queries can also eventually match with new or reformulated filtering queries.
The database of filtering queries of SAIC Brokers are indexed to be used by: a) the SAIC Filtering Service; b) by the Harvest Index/Search Subsystem and other Facilitators that provide search services. This way, Providers can look for Consumers in the SAIC Brokers by searching the indexed database of filtering queries.
In the SAIC Filtering Service, Consumers in general (including Facilitators), can subscribe filtering queries in the SAIC Brokers. Consumers can still use the Harvest Index/Search Subsystem services to search the Broker's database of MetaInfos (those gathered MetaInfos). Consumers can also use others Facilitator's services (like Discover [24] , which provides query refinement and query routing. Discover can be adapted to operate on the InfoMarket Niches).
The SAIC Dissemination Service is concerned with replication, caching and transmission of information flows inside the InfoMarket. The SAIC Dissemination also sees the InfoMarket as a hierarchy of Niches, but each Niche Broker may have a group of distributed replicas. Fig.5 illustrates the replication groups in a sub-tree of the Hierarchy of Niches.

Fig.5 Replication groups in a sub-tree of the Hierarchy of Niches
The replication of Broker (or, of Broker parts) improves access latency and avoids the overloading of very accessed Brokers. The replication of Brokers is realized using services like Harvest Replicator Subsystem or Wlis Servers [25] - whose replication service organizes the replicas in groups, limiting the size of the consistency state that each replica keeps and then minimizing the time to reach a consistent state. Services like Harvest Replicator also have the advantage of computing a good logical topology to propagate the updates between the replicas.
The use of caching services is vital to reduce Internet traffic, as shown by [26], discussing the use of Harvest Object Cache.
With the replication of the Niches Broker, two kinds of information transmission flows are proposed in order to improve the SAIC:
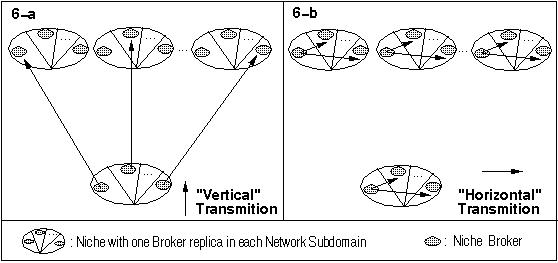
Fig.6 Transmissions "Vertical" (VT) and "Horizontal" (HT)
In a sub-tree of the Niches Hierarchy, the HT in each Niche+S minimizes the SAIC Filtering Service in the Niche+G, because the Niche+G stores only one filtering query of each Niche+S.
Still considering a sub-tree of the Niches Hierarchy, the HT in the Niche+G distributes the operation of the SAIC Filtering Service between the BrokerN+G replicas that belong to this Niche+G, because each replica of BrokerN+G store the filtering query of the BrokerN+S that is physically closer (as illustrated in Fig.6-a). So, the VT occurs between replicas of BrokerN+G and BrokerN+S that are physically closer (in the ideal case, they belong to the same Network Subdomain ).
Both VT and HT compress the MetaInfos and store them in a single file that is transmitted via a single connection. Communication protocols like HTTP-NG [27] should be used to improve performance and provide essential services (e.g. Security, Authentication, Charging, etc).
In the InfoMarket complex and dynamic scenery, the SAIC must evolve continuously, to quickly adapt to changes. Object-Oriented technologies are ideal for the SAIC implementation, for example, the use of Object-Oriented Databases (OODB) integrated with WWW (as described [28]) and the use of Common Object Request Broker Architecture (CORBA) integrated with WWW (as described [29]).
However, the SAIC implementation must consider the existing non-OOriented information systems that uses the WWW (especially the cooperative ones like [30]). In this case, Harvest technology can still be used because it allows the information extraction in non-OOriented filesystems to generate MetaInfos and export them to the InfoMarket.
We proposed the Services to Aid Information Consumption (SAIC) in the WWW. The SAIC allow the construction and maintenance of the Information Market - where Consumers and Providers realize Information Consumption (InfoCons). We defined the concept of InfoCons and described the Gathering, Filtering and Dissemination services - whose operations are distributed and scalable. The SAIC allow that Providers supply information and Consumers demand information converge to their respective information Niches (i.e. their respective semantic space), and in the Niches, Consumers and Providers can look for each other.
[1] C. Mic Bowman, Peter B. Danzig, Darren R. Hardy, Udi Manber and Michael F. Schwartz, "The Harvest information discovery and access system", 2nd WWW. Int. Conf. Computer Networks and ISDN Systems 28 (1995) 119-125 ftp://ftp.cs.colorado.edu/pub/cs/techreports/schwartz/Harvest.FullTR.ps.Z
[2] Altavista http://www.altavista.digital.com
[3] Yahoo http://www.yahoo.com
[4] Inference http://www.inference.com
[5] Lycos http://www.lycos.com
[6] Infoseek http://www.infoseek.com
[7] Excite http://www.excite.com
[8] T.W. Yan and H. Garcia-Molina, "SIFT - A Tool for Wide-Area Information Dissemination", Proc. Usenix Tech. Conf., Usenix, Berkeley, Calif, 1995, pp. 177-186; http://sift.stanford.edu
[9] Darren R. Hardy and Michael F. Schwartz "Scalable Internet Resource Discovery Among Diverse Information". Technical Report CU-CS-650-93, Department of Computer Science, University of Colorado, Boulder, May 1993. ftp://ftp.cs.colorado.edu/pub/cs/techreports/schwartz/Essence.Jour.ps.Z
[10] Harvest Broker Subsystem. http://www.transarc.com/afs/transarc.com/public/camargo/broker.ps
[11] Manber, Udi and Wu, Sun. "GLIMPSE: A Tool to Search Through entire File Systems" Proceedings of the USENIX Winter Conference}, San Francisco, California, p.23-32, Jan.1994. ftp://cs.arizona.edu/reports/1993/TR93-36.ps.Z
[12] WAIS http://www.wais.com/
(freeWAIS ftp://ftp.cnidr.org/pub/NIDR.tools/freewais/
[13] Nebula ftp://ftp.cs.psu.edu/pub/bowman/doc/iins.ps.Z
[14] Verity http://www.verity.com (1995)
[15] GRASS Geographic Resource Analysis Support System http://www.cecer.army.mil/grass/GRASS.main.html (1995)
[16] Danzig, Peter, et al. "Massively Replicating Services in Autonomously Managed Wide-Area Internetworks" Technical Report, University of Southern California, Jan.1994. ftp://catarina.usc.edu/pub/kobraczk/ToN.ps.Z
[17] Schwartz, Michael F. et al. "A Hierarchical Internet Object Cache." Technical Report 95-611, Computer Science Department, University of Southern California, Los Angeles, California, Mar.1995. ftp://ftp.cs.colorado.edu/pub/cs/techreports/schwartz/HarvestCache.ps.Z
[18] Clairmont Borges, José V. de Lima, "A Study of Some Facilitators", (in Portuguese) Tech.Report, 1995, ftp://caracol.inf.ufrgs.br/pub/www/TR-Facilitators.ps.Z
[19] "Harvest Project Status and Directions." http://harvest.transarc.com/
[20] Netscape Catalog Server. http://home.netscape.com/comprod/server_central/support/faq/catalog_faq.html
[21] Yahoo History. http://www.yahoo.com/docs/pr/history.html
[22] T.W. Yan and H. Garcia-Molina, "Information Finding in a Digital Library: the Stanford Perspective", SIGMOD Record, Vol.24, No.3, Sep.1995, pp. 62-70.
[23] Gerard Salton, "Automatic Text Processing", Addison Wesley, Reading, Massachusetts, 1989.
[24] Mark A. Sheldon, Andrzej Duda, Ron Weiss, David K.Gifford, "Discover: a resource discovery system based on content routing" Proc. 3rd Int. WWW Conf. Computer Networks and ISDN Systems, v27, 1995, pp. 953-972.
[25] Michael Baentsch, Georg Molter, Peter Sturm, "Introducing application-level replication and naming into today's Web", Proc. 5th Int. WWW Conf. Computer Networks and ISDN Systems, v28, 1996, pp. 921-930.
[26] Donald Neal, "The Harvest Object Cache in New Zealand", Proc. 5th Int. WWW Conf. Computer Networks and ISDN Systems, v28, 1996, pp. 1415-1430.
[27] HTTP-NG. http://www.w3.org/hypertext/WWW/Protocols
[28] Jack J. Yang and Gail E. kaiser, "An architecture for integrating OODBs with WWW". Proc. 5th Int. WWW Conf. Computer Networks and ISDN Systems, v28, 1996, pp. 1243-1254.
[29] Philippe Merle, Christophe Gransart, Jean-Marc Geib, "CorbaWeb: A generic object navigator". Proc. 5th Int. WWW Conf. Computer Networks and ISDN Systems, v28, 1996, pp. 1269-1281.
[30] Mike Crandall, Mark C. Swenson, "Integrating electronic information through a corporate Web" Proc. 5th Int. WWW Conf. Computer Networks and ISDN Systems, v28, 1996, pp. 1175-1186.