

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 1027.
This paper to be submitted to the Fifth International World Wide Web Conference.
Document last altered by Les Carr at Mon Jan 29 17:56:10 GMT 1996
This paper contrasts this approach to link management with the more generally accepted (and safer) solution of a closed information environment (perhaps in the form of an object-oriented SGML database), and presents an expanded open hypermedia service for the WWW composed of link management together with document management and consistency maintenance tools.
Each linkbase in the DLS makes links between source and destination documents which can in turn be stored on other sites. Although it conforms well to the HyTime [HyTime] model of independent links, it raises problems of keeping track of the documents to which each link points, as well as making sure that the link stays consistent with the (possibly changing) contents of the remote documents.
As if that is not enough, complications are added by the functionality of the DLS itself. Although the original versions of the software assumed that the linkbases would be resident on the host that was running the server software, later versions allow the server to access linkbases stored anywhere on the Web by specifying a URL. So we see a situation where not only the source and destination documents are not under the authors control, but neither are the links themselves (see Figure 1)!
| Figure 1: Relinquished Control in a Distributed Hypertext Environment | ||
|---|---|---|
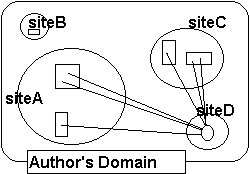 1a: User controls all documents and links | 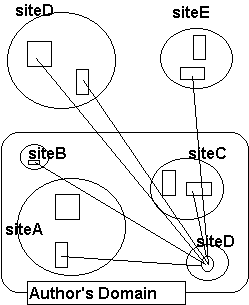 1b: User controls few documents and all links | 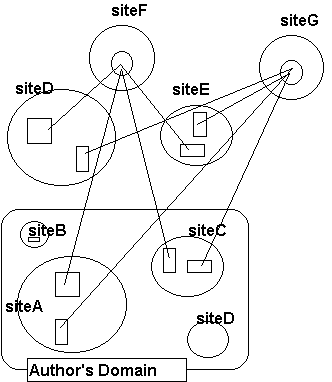 1c: User controls few documents and few links |
Beyond this requirement is the need to maintain the information environment, to check the availability of the remote resources, and to ensure the continued validity of the links (this situation is of course familiar to any user of the Web who maintains a list of links to their favourite Web sites). In the following sections we will discuss the use of some simple document and link management and maintenance software to help with these tasks in the context of creating hypertexts (or webs) which are designed to span many domains of authority: i.e. authoring beyond the confines of a single site.
This poses an interesting challenge for the Web's semi-co-operative global environment: is it possible to expand the coherence found in single document or in a supervised hypertext (created by an individual or planned collaborative effort) into a some form of global coherence? Or must a hypertext necessarily fragment into a hyperbase beyond a certain scale?
Experience has shown that Web documents are frequently divided into content-bearing documents (typically not making much use of links) and catalogue documents, not containing much content, but containing a large number of links. In effect, the coherence exhibited in the global hypertext is either at a very local level (within individual documents or in closely clustered groups of documents) or artificially superimposed as an organisational convenience (navigational shortcuts from one site to another).
One feature of the Web is the mixture of co-operative and autonomous components of its use. The organisation of each Web site is independent of any of the others, but the details of this organisation, and summaries of the available data are shared co-operatively with other organisations, and frequently published by `key' sites to the benefit of everyone. In contrast, the authoring of the documents at each site is typically performed in isolation, and without reference to the documents available elsewhere on the network. A co-operative effort may be involved within a site to make its collection of documents coherent, but this breaks down at the larger scale and is not exhibited between sites. In other words, according to [Stotts91], at a certain scale the Web ceases to be a hyperdocument (no authored intent and no coherence) and becomes a hyperbase.
The point at which this transformation occurs is the point at which the Web as a hypertext becomes difficult for a reader to use. Accordingly a key feature of a hyperbase is the need to supplement link following with data querying as an information discovery strategy. Up to recently, with the patchy coverage of most search engines, this was not a viable option. However the advent of more sophisticated Web searchers (such as Digital's Alta Vista service) has made this strategy much more useful.
The exact scale at which the transformation between hyperdocument and hyperbase occurs is not fixed: it is certainly possible to store a collection of mainly unrelated articles as a single resource (or even a single document): this is a hyperbase at a very localised scale. Conversely, it should be possible to author a document which draws together information in resources across the global network, from widely diverse sites: this is a hyperdocument (see Figure 2) at the global scale. The facilities of the DLS, which allow an author to create links between arbitrary Web documents and then to publish those links for the benefit of other users, provide a basis for producing such a global hyperdocument.
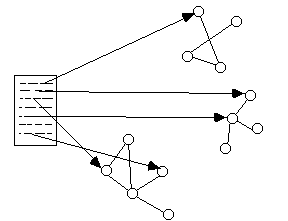
Experience with extrapolating local information collections onto a distributed platform such as the Web [De Roure95] shows that a clearly structured information design based around the aggregation of resources is highly useful. Collecting individual documents and multimedia information 'assets' into resources allows a degree of abstraction and helps to promote information re-use [Davis93]. A resource may collect together not only documents, but also linkbases suitable to help browsing the documents. The linkbases may be classified as internal to overlay a particular structure onto the resource and define a user's navigation through the assets contained in the resource, or as external to take readers to related materials in other resources, or to bring readers from other resources into this one.
Collections of these resources are considered hypermedia applications [Goose96], the published information environment. (The use of the word application in this context is unfortunate, but historical.) For example, a Biology application may consist of three resources:
Taken together, these parts form a whole whose coherence is derived from the author's strategy partly in creating documents (lecture notes), partly in defining suitable links and partly in identifying suitable material to join together. The 'whole' is capable of being extended still further by having extra resources added such as student essays or quizes, each of which would be retrospectively linked into the existing corpus by the existing links. [Hall95] discusses an example of this technique in a non-distributed context, but note that in this example, the documents that compose the dictionary and textbook may well not be available at the same site as the lecture notes and links.
This example clearly demonstrates the need to keep track of the components of the various resources being used, especially where resources may be added in a modular, plug-and-play fashion. The Document Management System (whose user interface is shown in figure 3) is a fulfilment of this requirement. (The name is historical and unfortunate because documents are not managed in the sense of being controlled.) The DMS deals with docuverses (a term coined by Ted Nelson [Nelson87] to refer to the universe of documents, but used here specifically to refer to the universe of documents with respect to a particular resource) which hold references to documents, linkbases and other docuverses. Figure 3 shows a docuverse (the 'root') which contains docuverses relating to various aspects of our home city, and a set of documents about the shopping facilities; the user interface is modelled on the familiar File Manager metaphor from Microsoft Windows 3 operating system. When the user starts to browse a docuverse, all the documents referenced by that docuverse are displayed on the right, together with any docuverses referenced on the left. A docuverse is represented by an open folder icon if it is either the 'current docuverse' (i.e. its documents are being shown on the right) or if it is an 'ancestor' of the current docuverse (the equivalent of being 'on the path' in the File Manager metaphor). Clicking on any docuverse makes it the current docuverse, and lists its files on the right of the screen. Clicking on any of the document icons retrieves that document from the Web and displays it in the current Web viewer.
All of these operations are performed with respect to an arbitrary 'root' docuverse, from which all the operations start. The root is probably associated with the user and served from that user's home machine, but any subsequent docuverse may (and probably will) reside on a different machine from its ancestors. Each resource is described by a docuverse, and each application is described by a docuverse that points at many resource docuverses.

<document> <URL>http://journals.ecs.soton.ac.uk/ <title>Open Journal Project <keywords>electronic publishing, electronic libraries, hypertext <type>HTML<time-stamp>Tue Aug 29 11:53:40 BST 1995 <document> <URL>http://bedrock.ecs.soton.ac.uk/Microcosm/papers.html <title>Microcosm Literature <keywords>hypertext, open hypermedia <type>HTML<time-stamp>Mon Jan 11 12:26:32 GMT 1994 <document> <title>All About Southampton <URL>http://journals.ecs.soton.ac.uk/dms/soton.docu <keywords>Southampton, leisure, geography <type>docuverse<time-stamp>Mon Jan 29 11:29:13 GMT 1996
The DMS is a mechanism to support post hoc integration of online multimedia information assets via the DLS, and is useful for specifying, visualising and building distributed information applications. It is currently under development and at an early stage of implementation, but initial trials seem to suggest that it will prove increasingly valuable as its user interface improves.
The DMS provides similar services to the bookmark facilities of many Web browsers. The difference is that the lists are distributed across many sites and intended to be shared by many users. Similar (but more developed) work is being done by other sections of the Internet community, for example the use of IAFA templates for resource description, or WHOIS++ for resource discovery (see [Hiom95] for a description of these technologies). Where the DMS approach outlined here differs is that each resource description unit (the docuverse) is intended to be used as a building block in constructing a large, distributed information application.
The much larger problem, mentioned previously, is that of resource consistency. If an author is collecting information (meta-data or link information) about documents that they have no control over, then the information may decay over time, breaking the links or rendering the DMS browser useless. Other systems provide environments which make this impossible, and we focus on Hyper-G [Andrews95], a well-known example of such system, in this section.
In contrast to the DMS, one of the main characteristics of Hyper-G [Flohr95] is its guarantee of consistency: its undertaking to keep strict track of all documents and interdocument hypertext links which it handles. Hyper-G has a superficially similar architecture to the World Wide Web: client browsers are provided documents by network servers, but like the DLS and unlike the Web the hypertext links are stored independently. Hyper-G provides support for link maintenance and management, linking between different media types, different sets of links for different users, a docuverse, text retrieval and some visualisation tools for navigating around 'clusters' of related materials.
Each Hyper-G server maintains its own document management system, which keeps the attributes of the documents on the server, a link database which maintains the links, and an information retrieval engine, which can retrieve on both the attributes of the document and also the full text content of the document. The servers themselves may be arranged into hierarchies underneath a world wide 'root' server, but the user connects directly to only one server. Hyper-G can also arrange to collect documents from other servers such as Web and Gopher servers.
The Hyper-G client browsers provide an interface for document and catalogue browsing, authoring and link creation, supporting a variety of standard text, picture, movie and 3D data formats.
Both within documents and between documents hypertext integrity is maintained by the authoring clients. Each document knows the id's of all the links it uses, and even though they are stored externally when a client loads a document it is also able to load all the links it requires. The client is then able to edit the document (or move it or delete it) without causing integrity problems, since at the client end all links are effectively embedded within the document.
The advantage then of the Hyper-G service (or of any hyperbase service), is that it forms an enclosed world of documents: its docuverses contain not just of references to the documents and links, but the documents and links themselves. The disadvantages of this service are that the documents have to be imported into the environment from their development environment, that they have to be translated into a format for which a Hyper-G viewer has been written, and, more generally, that they have to be owned by the database, i.e. brought into the author's domain of authority (in other words you can't link things you don't own).
Similarly, DLS links consist of references into objects within documents, rather than marked up links. These links may be fragile if the content of the document changes, leaving the pointer referencing the wrong object within the data. This is known as the editing problem. However, the advantage of this system is that one can make links in other peoples' data. The fragility of this system may seem at first sight to be an intolerable problem. Of course we are all familiar with the problem of dangling links in the Web, but the situation with the DMS is no worse. In fact it can be considerably better.
The advantage of the DMS is that it creates a closure of all the documents we are interested in, and provides an explicit list of those resources. This makes it very easy to produce tools which can iterate over the documents in the list: such tools can then regularly check that each server and document known to the DMS is still accessible, and can check, using the HEAD command of the HTTP protocol, that the document has not modified. The DMS may be used to indicate if there has been a problem accessing a document, for example by colouring the document icon. If the document continues to be inaccessible, its record in the DMS could simply be garbage-collected.
A further possibility, using the DMS, is to store a local copy of any document that is referenced. If the Web document then became inaccessible we could offer the user the opportunity to view the locally stored copy. This version may not be as up-to-date as the remote copy, but might still give the user the information that was required. Alternatively, if the referenced document is updated, then the DMS is capable of displaying a summary of changes, if the user is interested.
The situation with links in the DLS is also better than it might appear at first. The DLS does not mark-up link anchors within the text. The start anchor of DLS links is defined by the text string from which the link can be followed, and optionally by the name of the document. Thus a link might be available from any occurrence of a particular text string ( a generic link) or from any occurrence of that string within a particular document (a local link). Such anchors are not affected by changing the position of the string(s) within the document. The end anchor of the DLS link is a point within a document, and the intended position of this point might be affected if the document is altered.
There are a number of ways of dealing with this. We might make links only to the top of documents or we might express links in terms of the first occurrence of some string, rather than in terms of a position within a file. In any case, the DLS is always able to warn the user if the document has changes (and thus that the end of the link may be wrong) since it keeps the date that the document was last modified at the time that the link was made, as information inside the link. If at some subsequent traversal of the link the DLS observes that the date is no longer correct, it can warn the user. Again, because the links are stored explicitly, we can build tools to iterate over the links and discover which links dangle, or point to documents that have changed, so that dangling links may be garbage collected, and users may be warned of links with suspect pointers.
By taking advantage of the docuverses we can compensate for some of the pitfalls of the open model. These strategies (currently under development) provide a way of adding varying degrees of 'closedness' for applications that require some form of guarantee of the availability of data. This guarantee is in the form of post-hoc resource checking, but could be extended to provide agent-based pre-emptive polling strategies.
A problem for users of library information services in Higher Education is the isolated and diverse nature of the electronic information resources. Although a user can (in theory) from the same terminal access many dozens of journals, databases and articles on subjects of interest, it is necessary to navigate a complicated path through many providers information gateways in order to locate any particular piece of information of (as yet) undetermined relevance.
The goal of the project is to develop a framework of information retrieval technologies and electronic publishing practises to be used by information providers (especially journal publishers) which will allow them to make their publications available not as isolated, one-off resources, but as co-operating assets within an information delivery environment such as a library at an institution of Higher Education. This goal is to be achieved by using the DLS and DMS to seamlessly integrate journals that are available electronically over the network with other journals and information resources that are also available on the network.
The result of the first part of the project is to produce a demonstrator of the capabilities of the DLS and DMS: it is a more elaborate version of the biology application explained above, and consists of articles from a number of biology journals, online glossaries, protein databases, bibliographic databases and lecture notes. All these resources, some of which are owned by the project, and some of which are generic resources available on the Web, are linked together by DLS linkbases and presented using the DMS interface.
However, it is worth considering real world examples before jumping to this conclusion. Although a library is often considered to be a pre-eminent example of a controlled, closed information environment, [Levy95] challenges this description, since real world collections are subject to 'crumble', i.e. decay over time. Hence library catalogues (as well as the documents they describe) require constant and active maintenance, without which their consistency cannot be guaranteed. It is also the case that as information consumers in the real world we deal with uncertainty of access all the time: if the host site of some data is down, or there are network problems that stop us from reaching the site, (or indeed if the library is closed or a book has been borrowed) then we have heuristics that help us to take appropriate action and to continue our tasks. If we take this point of view then we may decide to work with any potential uncertainty, especially in order to gain the benefits of an open environment, and to develop futher safeguards for an open environment by implementing constant docuverse monitoring, or designing a way of declaring exception handling facilities within a docuverse.
Finally, let us mention two user groups on the Web. Commercial users who maintain a WWW site to distribute their own company and product information are likely to benefit from a closed, hyperbase-style system that is especially suitable for single-site hypertexts. In contrast, the academic community has been impacted by the online publishing phenomenon in a different way ([Harnad90]). Consequently online scholarly communities are forming that require shared, distributed publishing facilities where an open model would excel.
 Leslie Carr
is a Senior Research Fellow in the University of
Southampton’s Multimedia Research Group. His research interests
include the application of HyTime, SGML and DSSSL to hypermedia
applications, in particular WWW, and he menages the Open Journal
Framework project and the ongoing development of the Distributed
Link Services.
Leslie Carr
is a Senior Research Fellow in the University of
Southampton’s Multimedia Research Group. His research interests
include the application of HyTime, SGML and DSSSL to hypermedia
applications, in particular WWW, and he menages the Open Journal
Framework project and the ongoing development of the Distributed
Link Services.
Gary Hill
No biographical information available.
http://www.ecs.soton.ac.uk/user/gjh
David De Roure
is a lecturer in Computer Science at the
University of Southampton, UK, researching into distributed
systems and in particular addressing the scalability and
complexity of networked information systems. David leads the
Distributed Systems and Multimedia Networking activities in the
Multimedia Research Group.
http://www.ecs.soton.ac.uk/user/dder
Wendy Hall
is a Professor of Computer Science at the University
of Southampton. She is variously a Director of the Multimedia
Research Group, the University’s Interactive Learning Centre and
the Digital Library Centre, researching into multimedia
information systems and their application to industry, commerce
and education.
http://www.ecs.soton.ac.uk/user/wh
Hugh Davis
is a lecturer in Computer Science at the University
of Southampton, UK, and was a founder member of the multimedia
research group. He was one of the inventors of the Microcosm open
hypermedia system, and is manager of the Microcosm research
laboratory. His research interests include data integrity in open
hypermedia systems and the application of multimedia information
retrieval techniques to corporate information systems and to
digital libraries.
http://www.ecs.soton.ac.uk/user/hcd