

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 931.
The World Wide Web[1] has spawned the creation of many Web browsers, each of which is "programmable" via the common HTML standard. These Web browsers form a platform on which software developers can build clients for Client/Server systems. A "mediator" can be created that acts as a gateway between the Web browser clients and the existing server. In a Client/Server architecture where the client software does nothing more than display and format information retrieved from the server, a World Wide Web browser can be used as a replacement for the client software used by the human users of the system. In other systems, where the client software performs additional tasks on behalf of the server or the users, the mediator can perform this work on behalf of the Web browser-based clients.
Some have used CGI programs to accomplish the tasks of the mediator[2]. A normal HTTP server is set up somewhere on the same LAN as the existing server application. specialized CGI programs are written to handle user requests, and the user is presented with an HTML Forms-based interface. This is unsatisfactory for a number of reasons:
It may also be possible to use browser-specific tools like Mosaic's CCI[4] and Netscape's Plug-In APIs[5] to create Web browser based clients for Client/Server systems. However, using these APIs limits the use of the resulting Web-based client software to specific platforms and specific Web browsers. This is an unnecessary limitation which negates many of the benefits of creating a Web-based client.
Every Web browser available today supports the use of an HTTP proxy[6] for retrieving documents on behalf of the Web browser. These proxies are often used to give Web access to users behind an Internet firewall or other system that restricts access to corporate networks. When a Web browser user requests a document, rather than connecting directly to the site specified in the document's URL, the Web browser contacts the HTTP proxy. This proxy then fetches the document on behalf of the Web browser, feeding the information back to it.
HTTP proxies and HTTP servers can be used to create mediators that allow Web browser clients to access the existing server in a Client/Server system. This approach allows for the easy migration of Client/Server applications and their data to the World Wide Web. This mediator-based approach does not require any changes to the existing application server code.
This paper proceeds as follows. First, we describe the motivation for our use of HTTP proxies as a method of connecting an existing Client/Server system to the Web. Then, we list the requirements our method would have to fulfill. Next, we describe the architecture we've developed for moving existing Client/Server applications to the Web. We describe in detail one example of using this approach, in which we describe using the architecture to move an existing Client/Server system to the Web. Finally, we consider some future work and extensions to the research presented here.
The HTTP proxy (or "mediator") can be run on the same machine as the
original server application or it can reside on a LAN attached to the server
machine. It does not need to run on the same computer as any of the Web
browser users, and a single mediator can be used to translate requests
from multiple Web-based users of the system. This solves the resource
problem of having one mediator per Web-based user.
There are a few different possible approaches to creating the mediator:
Our architecture supports all of these methods of creating the mediator. In
addition, a variant of the above architecture is possible which does not use
an HTTP Proxy server. Many of the newer HTTP servers (including Netscape's
servers[7] and Apache[8])
support APIs which allow code to be linked directly into the running server.
Using these APIs, it may be possible to turn an ordinary web server into a
mediator in our architecture.
Another problem complicating our architecture is the need to have certain
HTML files served directly by the mediator. There may be URLs handled by
the mediator which do not translate into commands for the existing server.
These URLs may, for example, provide the HTML user interface for the system
or provide help information to new users of the system. To solve this
issue, the mediator maintains a small document tree out of which it serves
HTML files. When the mediator receives a request from a Web client, it must
decide if the the request is to be gatewayed to the server or if it is to be
answered with a document from the mediator's own document tree.
In addition to these complications is the serious question of how to handle
application-specific functions that the original clients handled on
behalf of the server. These include invoking external tools and using
platform specific libraries, devices, or operating system services. These
application-specific features of the existing client often cannot be
emulated by a Web browser client using only HTML. A number of techniques
can be used to solve these issues:
Architecture
In order to connect an existing Client/Server system to the Web while
fulfilling all the requirements stated above, we decided on an architecture
that interposes an HTTP proxy between the Web-based clients and the
existing application server (Figure 1). This HTTP proxy has been designed to intercept
HTTP requests for data and transform them into requests for the legacy
system using its native protocols.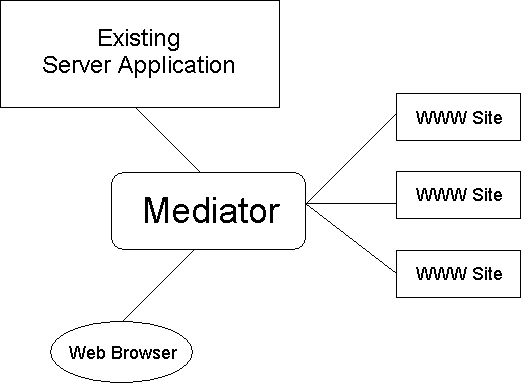
When adding a Web interface to a system for which source is not
available (perhaps a commercial software package) or when it is not
feasible to change the source to any piece of the system, it is possible
to build the mediator from scratch. If the protocols used between the
server and client are known, the mediator can be created as a new
"client" for the system. If the existing clients or server for the
system allow for extensions via scripting languages or the ability to
employ external tools, it may be possible to "hook in" the mediator's
HTTP proxy code with the existing client.
In this approach, an existing client for the Client/Server system is
modified to behave as an HTTP proxy server. When the new HTTP proxy
portion of the code receives a request from a Web browser client, it
simply sends the request on to the server as though it had received that
request normally.In a system where the server code is large and complex
and the client code is simpler, this approach can allow for fewer
changes to existing code.
In some cases, it may be possible to modify the Client/Server system's
server code to directly interact with Web browsers. This will depend
heavily on whether or not the server relies on existing clients being
"stateful", that is, remembering application state across requests. In
some systems, this may be preferable to modifying a client of the system
as the client code may actually be more complicated than the server's
code.
It may be preferable to base the mediator on an existing client for the
system as well as modify the server to behave differently when
interacting with the new client. This may be necessary if the server
expects each client of the system to represent only one user, since in
our architecture, a single mediator is responsible for multiple Web
based users of the system. Modifications to the server code and/or the
protocol used between the server and the new "mediator client" may be
necessary to achieve this one-to-many mapping.Challenges to our architecture
Several factors complicate our architecture. First, the HTTP protocol is
completely stateless, while many existing Client/Server systems use stateful
protocols. With the current HTTP specification, Web browsers connect to a
server, send a request, receive the response, and then close the
connection. The specialized clients in most Client/Server systems open a
connection to the server and then leave that connection running for the
entire lifetime of the session. In order to emulate this behavior with Web
based clients, the mediator can do several things:
It is possible to embed so-called "magic cookies" into the HTML sent
down to the Web browsers by the mediator. These cookies allow the
mediator to identify each browser independently, allowing state
information on a per-browser basis to be kept. This approach is
problematic, since it is impossible to determine when a Web browser
client of the system has crashed and restarted. In this case, the
mediator may have to abort transactions on behalf of the crashed client,
carry out its portion of some disconnection or fault tolerance protocol,
etc. Since it is impossible to determine when a client has crashed, the
mediator must pick some arbitrary means of determining this information,
perhaps basing it on idle time or some other imperfect method.
This method is an expansion on the magic-cookie based approach to
identifying Web clients. In this case, the magic cookies are generated
on a per client basis and are changed with each command the browser user
executes via the mediator. In this way, each request to the mediator
contains the state of the requesting Web client embedded directly into
it. Thus, the mediator can determine from each request the previous
requests the user has already completed successfully.
It may be possible for the mediator to perform some of these client tasks
itself, on behalf of the Web browser clients. This is true in the case of
invoking external tools in a batch fashion, simply running them on certain
input and collecting their output. These batch tools require no
intervention by the user during their runtime. This may also be possible in
the case of invoking X-windows based interactive tools when both the
mediator and the Web-based clients are running on X displays. In this case,
the mediator starts the tool on its machine and has the tool display its
interface on the user's X display.
In the case of tools or services that must be used on the Web client's
local computer, it is possible to create a platform-specific MIME helper
application, which is run in response to a new MIME type sent down to the
browser by the mediator. For example, it is possible to set up all Web
browser to run an application called "Foobar" when it receives an "X-Foobar"
MIME message. Since each HTTP response includes a MIME type specifier, the
mediator simply tells the browser that the response is of the "X-Foobar"
type, and the browser will then run the "Foobar" application.
For better integration between the Web browser and the helper application,
browser-specific code can be written using the various APIs provided by the
different browser vendors. For example, if the system designer knows that
all Web-based users will be using Netscape's Navigator as their browser, he
or she can create a Netscape Plug-In that handles the new "X-Foobar" MIME
type sent by the mediator. These APIs allow code to be written that is
executed directly in the browser window, maintaining the seamless
integration of the Client/Server system with the Web browser.
Java (and other so called mobile code systems including Omniware[10] and Grow[11] )applets allow
for similar extensions as the above mentioned browser-specific APIs. Their
major advantage is that they are not browser or platform specific, and so it
is possible to create portable extensions which maintain integration between
the Client/Server system and the Web browser.Example
The Oz system[12] is a Client/Server rule-based workflow
system currently targeted as a software development environment. The
clients for the system support the invocation of external tools to be used
during software development (i.e. the client is responsible for running the
compiling and editing tools used by the developers in the system).
Over the course of its research, our group has developed several clients for use with the Oz system, including a TTY-based client, an Xview client, and a Motif client. In creating our mediator, known as "OzWeb", we decided to base our work on the TTY client. We were aiming to create a mediator that had no user interface -- it was to run as a daemon process on a machine connected to a LAN. While X toolkits like Xview and Motif allow for the creation of an application without any windows, it was easier to begin with a minimalist interface (like the one in our TTY client) and simply strip away any pieces we didn't need.
OzWeb is conceptually broken into two parts: a standard HTTP proxy, and code to communicate with our Oz server (see Figure 2). The HTTP portion simply receives requests for Web documents from clients and then handles the requests, funneling the data back to the Web browsers. The second portion, which communicates with our application server, receives HTTP requests and responds to them either by sending requests to our server software or by responding with HTML pages from OzWeb's document tree.
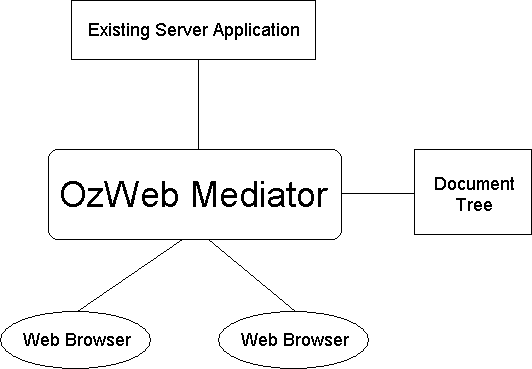
In order to determine what to do with a request from a Web browser, OzWeb looks at the URL in the request. If the URL refers to an Internet site, OzWeb retrieves the document on behalf of the Web browser. If the URL is of the form:
OzWeb contacts the Oz server to perform the command on behalf of the Web based user in the same manner that the TTY client would supply the command and its parameters. As mentioned in the Architecture section, certain URLs are handled by the HTTP Proxy itself, without contacting the server application. For example the main startup screen of our system is represented by the following URL:
http://oz/index.htmlThis URL presents the user with a message welcoming them to the system (Figure 3) and sets up the display and command choices that are to be shown to the user.
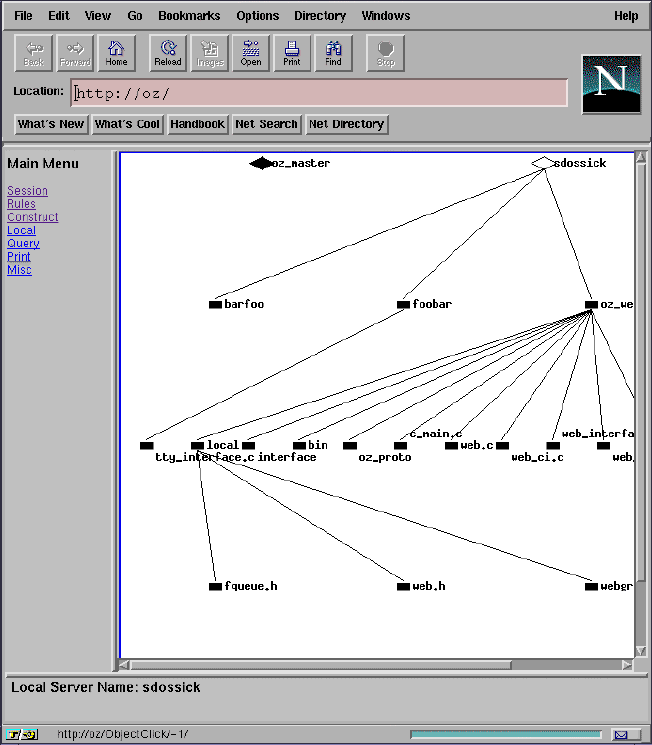
When OzWeb receives a request for a document, it checks the site field, and in this case, since the site field says "oz", it realizes that this is a request for the Oz system (as opposed to an actual request for a document from the Web).
In this case, OzWeb next looks to see if there is a command called "index.html" which is designated as a command which the server should handle. Realizing that this isn't an internal command, OzWeb attempts to find a file called "index.html" in its document tree. In this respect, it is acting as a mini Web server, not as a traditional HTTP Proxy. Upon finding the file called "index.html", OzWeb sends the contents of the file down to the Web browser and closes the connection.
The existing Oz client software relies heavily on the use of multiple windows as well as multiple independent window panes. It is not a simple interface to emulate. As a proof of concept, our first application of the OzWeb Proxy was to simulate as closely as possible the existing GUI Oz Client interface in the user's Web browser, using Netscape 2.0 Frames as the mechanism for mimicking the existing menus, pop-up windows, etc.
The Oz server relies on its clients to invoke the tools that are used in the course of software development. For example, when a user asks to compile a file, the server tells the client to run the compiler on a given source file. In the case of our system, we knew that all Web-based users would have X display access to the system running the OzWeb mediator. Because of this, we are able to have the mediator start the tools on behalf of the Web clients. If a tool is interactive, we rely on X access to make the interface appear on the user's screen (by resetting the X DISPLAY variable).
As discussed in the >Architecture section, in the case of a system where X display access is not possible, or where certain external tools or system libraries must be executed on the user's machine, it is possible to create a MIME content handler and a corresponding new MIME type that allows small pieces of specialized code to be run on the user's system.
The OzWeb mediator has been specifically designed so that a single instance of OzWeb can allow multiple users to access the system via the Web. An unlimited number of users can configure their browsers to use the OzWeb proxy as their HTTP proxy server, and they can all then access the Oz server. With many hundreds of users, it may be more practical to have a number of OzWeb proxy server machines, achieving a load balancing effect.
Great care was taken in the design of the OzWeb proxy server to make sure that NO state information is maintained by OzWeb itself. Instead, the HTML sent down to browsers as a result of executing a command in the Oz system is encoded in such a way as to make it possible to tell the last commands executed by the particular client. Each URL link in the resulting HTML has a parameter added. When the user clicks on one of these links, this parameter is sent to the mediator along with the rest of the URL. This allows the mediator to determine the sequence of commands the user has executed in the past.
Lotus' InterNotes[16] product uses CGI mechanisms to allow Web browser access to documents and forms managed by the Notes Server. Documents to be placed on the Web are pretranslated by a program that converts them to HTML. These documents and forms are accessed through a standard HTTP server as though they were normal HTML documents. In the case of Notes Forms, the Submit button sends the contents of the form to a Lotus-supplied CGI program that incorporates the data back into the Notes database. While this does allow for some Web-based use of their system, the interaction model is limited. Web-based users do not have access to the integrated email and applications which standard Notes clients use.
Barta et al.[17] describe a toolkit for the creation of "Interface-Parasite" gateways. These gateways allow a synchronous session-oriented tool, a telnet session for example, to be used via a Web browser. Their toolkit requires no changes whatsoever to the source code of the Server application, but their toolkit cannot handle an application in which the Client can perform actions independently of the server.
Ockerbloom[18] proposes an alternative to MIME types, called Typed Object Model (TOM), that could conceivably be employed instead of a MIME extension to allow the use of external tools in the client. Objects types exported from anywhere on the Internet can be registered in ``type oracles'', specialized servers that may communicate among themselves to uncover the definitions of types registered elsewhere. Web clients who happen upon a type they do not understand can ask one of the type oracles how to convert it into a known supertype. In this way, the Web clients would not have to be set up to handle a new MIME type. They could simply query the type oracle, which could return information on how to run the external tools.
We were able to achieve our goal of connecting to the mediator using the standard HTTP protocol and a standard Web browser (Netscape 2.0). Other browsers supporting the Netscape HTML extensions have been used as well.
We have already identified several areas for future work on our mediator-based approach to moving Client/Server systems to the Web:
Gail E. Kaiser
Gail E. Kaiser is a tenured Associate Professor of Computer
Science and the Director of the Programming Systems Laboratory
at Columbia University. She was as an NSF Presidential Young
Investigator in Software Engineering, and has published about 90
refereed papers in collaborative work, software development
environments, software process, extended transaction models,
object-oriented languages and databases, and parallel and
distributed systems. Prof. Kaiser is an associate editor of the
ACM Transactions on Software Engineering and Methodology and has
served on about 25 program committees. She received her PhD and
MS from CMU and her ScB from MIT.
http://www.cs.columbia.edu/~kaiser/
The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the US or NYS government, ARPA, Air Force, NSF, or NYSSTF.